logistic回归模型
logistic分布
定义logistic分布
F(x)=P(X≤x)=1+e−(x−μ)/γ1f(x)=F′(x)=γ(1+e−(x−μ)/μ)2e−(x−μ)/γ
分布函数图像是一条S形曲线,以点(μ,21)为中心对称,如下图
二项logistic回归模型
定义二项logistic是如下条件概率分布
p(Y=1∣x)=1+exp(w⋅x+b)exp(w⋅x+b)p(Y=0∣x)=1+exp(w⋅x+b)1
为了方便有时将偏置并入权重中,即w=(w(1),w(2),⋯,w(n),b)T,x=(x(1),x(2),⋯,x(n),1),同时***logistic***模型简写为
p(Y=1∣x)=1+exp(w⋅x)exp(w⋅x)p(Y=0∣x)=1+exp(w⋅x)1
定义对数几率(log odds)或***logit***函数为
logit(p)=log1−pp
对logistc回归而言
log1−P(Y=1∣x)P(Y=1∣x)=w⋅x
说明了在logistic回归中,输出Y=1的对数概率是输入x的线性函数;通过logistic回归定义模型可以将线性函数w⋅x转换为概率;
模型的参数估计
对于给定训练数据集可以应用极大似然估计法估计模型参数,
设
P(Y=1∣x)=π(x),P(Y=1∣x)=1−π(x)
似然函数为
i=1∏N[π(xi)]yi[1−π(xi)]1−yi
对数似然函数
L(w)=i=1∑N[yilogπ(xi)+(1−yi)log(1−π(xi))]=i=1∑N[yi(w⋅xi)−log(1+exp(w⋅xi)]
对L(w)求极大值,得到w的估计值;至此通常采用梯度下降法或者拟牛顿法来求解;
多项logistic回归
将其从二项推广到多项logistic回归模型
P(Y=k∣x)=1+k=1∑k−1exp(wk⋅x)exp(wk⋅x),k=1,2,⋯,K−1P(Y=K∣x)=1+k=1∑k−1exp(wk⋅x)1
同理,二项logistic回归的参数估计法也可以推广到多项logistic回归;
最大熵模型
原理
最大熵模型是概率模型学习的一个准则,最大熵原理认为,在所有可能的概率模型中,熵最大的是最好的模型,通常用约束条件确定概率模型的集合;设离散变量X分布是P(X),熵为
H(P)=−x∑P(x)logP(x)
且满足不等式
0≤H(P)≤log∣X∣
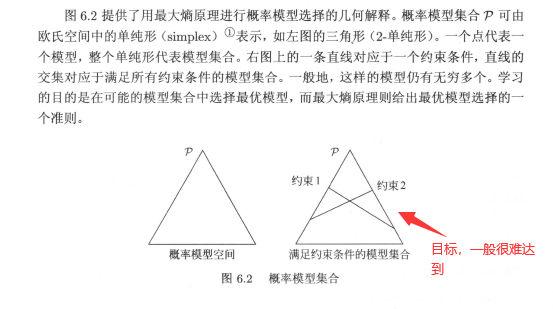
直观的,在没有更多信息的情况下认为不确定部分是等可能的,“等可能”不易操作,而熵则是一个可优化的指标以此来达到等可能的目的;
最大熵模型定义
对于给定训练数据集
P^(X=x,Y=y)=Nv(X=x,Y=y)P^(X=x)=Nv(X=x)其中v(X=x,Y=y)表示样本(x,y)出现的频数;
特征函数f(x,y)定义
f(x)={1,0,x与y满足某一事实否则
特征函数f(x,y)关于经验分布P^(X,Y)的期望值表示为
E_\hat p(f)=\sum_{x,y}\hat P(x,y)f(x,y)
特征函数f(x,y)关于模型P(Y∣X)与经验分布P^(X)的期望值
Ep(f)=x,y∑P^(x)P(y∣x)f(x,y)
如果模型能够获取训练数据中的信息,那么可以假设这两个期望值相等
E_p(f)=E_\hat p(f)
假设满足所有约束条件的模型集合为
C\equiv\{P\in p|E_P(f_i)=E_\hat p(f_i),i=1,2,\cdots,n\}
定义在条件概率分布P(Y∣X)上的条件熵为
H(P)=−x,y∑p^(x)P(y∣x)logP(y∣x)
则模型集合C中条件熵H(P)最大的模型为最大熵模型,其中的对数为自然对数;
最大熵模型的学习
最大熵模型的学习可以形式化为约束最优化问题;
对于给定的训练数据集T以及特征函数fi(x,y),i=1,2,⋯,n,最大熵模型的学习等价于约束最优化问题
p∈CmaxH(P)=−x,y∑P^(x)P(y∣x)logP(y∣x)s.t.Ep(fi)=Ep^(fi),i=1,2,⋯,ny∑P(y∣x)=1
按照习惯可以将其等价的改为最小值问题
p∈CmaxH(P)=−x,y∑P^(x)P(y∣x)logP(y∣x)s.t.Ep(fi)=Ep^(fi),i=1,2,⋯,ny∑P(y∣x)=1
求约束最优化问题就是求解最大熵模型。可以将约束最优化问题转化为无约束最优化的对偶问题。通过求解对偶问题来求解原始问题;
具体推导
引入拉格朗日乘子w0,w1,⋯,wn,定义拉格朗日函数L(P,w);
L(P,w)\equiv-H(P)+w_0(1-\sum\limits_yP(y|x))+\sum\limits^n_{i=1}w_i(E_\hat p(f_i)-E_p(f_i))\\
=\sum\limits_{x,y}\hat P(x)P(y|x)\log P(y|x)+w_0(1-\sum_yP(y|x))+\sum^n_{i=1}w_i(\sum\limits_{x,y}\hat P(x,y)f_i(x,y)-\sum_{x,y}\hat P(x)P(y|x)f_i(x,y))
最优化原始问题
p∈CminwmaxL(P,w)
对偶问题
wmaxP∈CminL(P,w)
由于拉格朗日函数L(P,w)是P的凸函数,原始问题与对偶问题是等价的(对偶问题的定理)首先记作
ψ(w)=p∈CminL(P,w)=L(Pw,w)
ψ(w)称为对偶函数,同时,其解记作
Pw=argp∈CminL(P,w)=Pw(y∣x)
具体的求L(P,w)对P(y∣x)的偏导数,令偏导数等于0,解得
P(y∣x)=exp(i=1∑nwifi(x,y)+w0−1)=exp(1−w0)exp(i=1∑nwifi(x,y))
由于y∑P(y∣x)=1,得
Pw(y∣x)=Zw(x)1exp(i=1∑nwifi(x,y))其中,Zw(x)=y∑exp(i=1∑nwifi(x,y))
之后求解外部的极大化问题
wmaxψ(x)
记其解为w∗,
w∗=argwmaxψ(w)
极大似然估计
对偶函数的极大化等价于最大熵模的极大似然估计;
证明过程:

这样最大熵模型的学习问题就可以转换为具体的求解对数似然函数极大化或对偶函数极大化的问题;写成更一般的形式
Pw(y∣x)=Zw(x)1exp(i=1∑nwifi(x,y))其中,Zw(x)=y∑exp(i=1∑nwifi(x,y))
深入理解
最大熵模型与logistic回归模型有着类似的形式,它们又称为对数线性模型(log linear model),模型学习就是在给定的训练数据集条件下对模型进行极大似然估计或正则化的极大似然估计;
事实上,定义特征函数,其中g(x)为提取出每个x的特征,,输出是x的特征向量:
{g(x),y=10,y=0
将以上特征带入到最大熵模型中
P(y=1∣x)=exp(wig(x))+exp(wi∗0)exp(wig(x))
上下同时除exp(wig(x)),得
P(y=1∣x)=1+exp(−wig(x))1
同理
P(y=0∣x)=exp(wig(x))+exp(wi∗0)exp(wi⋅0)=exp(wig(x))+11
自然的发现logistic回归模型其实就是最大熵模型在y=1时抽取x的特征这一情况;之前我们用极大似然估计求参数wi其实这样求出的模型就是maxPw(y∣x),所以就是求最大熵模型;
日常生活中,我们经常不知不觉的就是用了最大熵模型,这里给出了更高层面的抽象的最大熵模型;显然最后的例子也说明了logistic回归其实也是一种最大熵模型;
模型的最优化算法
逻辑斯蒂回归模型、最大熵模型归结为似然函数为莫表的最优化问题,通常通过迭代算法求解,从最优化的角度上来看这时的目标函数具有很好的性质,他是光滑的凸函数;因此多种最优化方法都适用;常用的方法有改进的迭代尺度法、梯度下降法、牛顿法、拟牛顿法。牛顿法或拟牛顿法;牛顿法或者拟牛顿法一般收敛速度更快;
最大熵模型
Pw(y∣x)=Zw(x)1exp(i=1∑nwifi(x,y))其中,Zw(x)=y∑exp(i=1∑nwifi(x,y))
对数似然函数
L(w)=x,y∑P^(x,y)i=1∑nwifi(x,y)−x∑P^(x)logZw(x)
改进的迭代尺度算法(IIS)
原理
IIS核心想法是:建设最大熵模型当前的参数向量是w=(w1,w2,⋯,wn)T,我们希望找到一个新的参数向量w+δ=(w1+δ1,w2+δ2,⋯,wn+δn),使得模型的对数似然函数值增大。如果能有一种参数更新方法让w→+δ,那么重复使用即可找到对数似然函数的最大值;
对于给定的经验分布P^(x,y),对数似然函数的该变量是
L(w+δ)−L(w)=x,y∑P^(x,y)i=1∑nδifi(x,y)−x∑P^(x)logZw(x)Zw+δ(x)
利用不等式
−logα≥1−α,α>0
则
−x∑P^(x)logZw(x)Zw+δ(x)≥x∑P^(x)(1−Zw(x)Zw+δ(x))≥x∑P^(x)−x∑P^(x)Zw(x)Zw+δ(x)≥1−x∑P^(x)Zw(x)Zw+δ(x)
L(w+δ)−L(w)=x,y∑P^(x,y)i=1∑nδifi(x,y)+1−x∑P^(x)y∑Pw(y∣x)exp(i=1∑nδifi(x,y))
右端记为A(δ∣w),于是
L(w+δ)−L(w)≥A(δ∣w)
如果能找到合适的δ使得下界A(δ∣w)提高,那么对数似然函数也会提高;然而,函数其中的遍量δ是一个向量含有多个变量,不易同时优化。IIS试图一次只优化其中一个变量δi,而固定其他变量;
为此引入一个新的量
f#(x,y)=i∑fi(x,y)
于是
A(δ∣w)=x,y∑P^(x,y)i=1∑nδifi(x,y)+1−x∑P^(x)y∑Pw(y∣x)exp(f#(x,y)i=1∑nf#(x,y)δifi(x,y))
由于f#(x,y)fi(x,y)≥0且i=1∑nf#(x,y)fi(x,y)=1,根据Jensen不等式,得到
exp(i=1∑nf#(x,y)fi(x,y))δif#(x,y))≤i=1∑nf#(x,y)fi(x,y))exp(δif#(x,y))
记A(δ∣x)改写后的为B(δ∣x)
B(δ∣x)=x,y∑P^(x,y)i=1∑nδifi(x,y)+1−x∑P^(x)y∑Pw(y∣x)i=1∑nf#(x,y)fi(x,y))exp(δif#(x,y))
于是
L(w+δ)−L(w)≥B(δ∣w)
显然其是对数似然函数的一个新的下界,求B(δ∣w)对δi的偏导数,并令其为0得到
\sum_{x,y}\hat P(x)P_w(y|x)f_i(x,y)\exp(\delta_i,f^\#(x,y))=E_\hat P(f_i)
依次对其求解可算出δ;
算法
*input:*特征函数f1,f2,⋯,fn,经验分布P^(X,Y),模型Pw(y∣x)
*output:*最优参数值wi∗;最优模型Pw
-
对所有的i∈{1,2,⋯,n},取初值wi=0
-
对每一i∈{1,2,⋯,n}
- 令δi是方程
\sum_{x,y}\hat P(x)P_w(y|x)f_i(x,y)\exp(\delta_i,f^\#(x,y))=E_\hat P(f_i)\\
其中,f^\#(x,y)=\sum\limits_if_i(x,y)
的解;
- 更新wi值:wi←wi+δi
-
若不是所有的wi都收敛,重复2
这一算法的关键一步就是2.1,求解其中的δi,如果f#(x,y)是常数,则可以显示的表示为
\delta_i=\frac1M\log \frac{E_\hat p(f_i)}{E_p(f_i)}
若f#(x,y)不是常数,那么必须通过数值计算δi,简单有效的方法就是拟牛顿法;
以g(δi)=0表示2.1中的方程,牛顿法通过迭代求得的δi∗,使得g(δi∗)=0,迭代公式
δi(k+1)=δi(k)−g′(δi(k))g(δi(k))
只要适当的选取初始值δi(0),由于δi的方程有单根,因此牛顿法恒收敛,而且收敛速度很快;
拟牛顿法
对于最大熵模型而言
Pw(y∣x)=y∑exp(i=1∑nwifi(x,y))exp(i=1∑nwifi(x,y))
目标函数(极大化似然函数就等价于)
w∈Rnminf(w)=x∑P^(x)logy∑exp(i=1∑nwifi(x,y))−x,y∑P^(x,y)i=1∑nwifi(x,y)
梯度
g(w)=(∂w1∂f(w),∂w2∂f(w),⋯,∂wn∂f(w))T
其中
∂wi∂f(w)=x,y∑P^(x)Pw(y∣x)fi(x,y)−EP^(fi),i=1,2,⋯,n
最大熵模型学习的BFGS算法
input:特征函数f1,f2,⋯,fn;经验分布P^(x,y),目标函数f(w),梯度g(w)=Δf(w),精度要求ϵ
output:最优参数值w∗;最优模型Pw⋅(y∣x)
- 选定初始点w(0),取B0为正定对称矩阵,置k=0;
- 计算gk=g(w(k)),若∣∣gk∣∣<ϵ,则停止计算,得w∗=w(k),否则跳转3;
- 由Bkpk=−gk求出pk;
- 一维搜索:求λk使得
f(wk+λkpk)=λ≥0minf(w(k)+λpk)
- 置w(k+1)=w(k)+λkpk;
- 计算gk+1=g(w(k+1)),若∣∣gk∣∣<ϵ,则停止计算,得w∗=w(k),否则求出Bk+1
Bk+1=Bk+ykTδkykykT−δkTBkδkBkδkδkTBk其中,yk=gk+1−gk,δk=w(k+1)−w(k)
- 置k=k+1,转至3;

