Basic
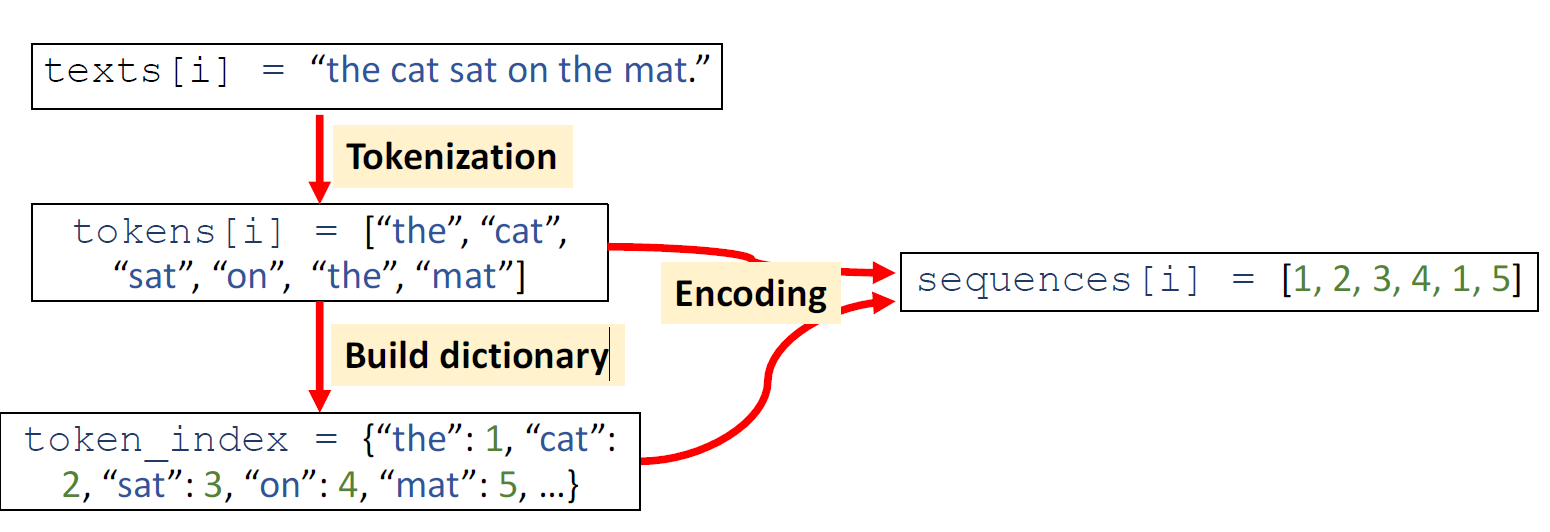
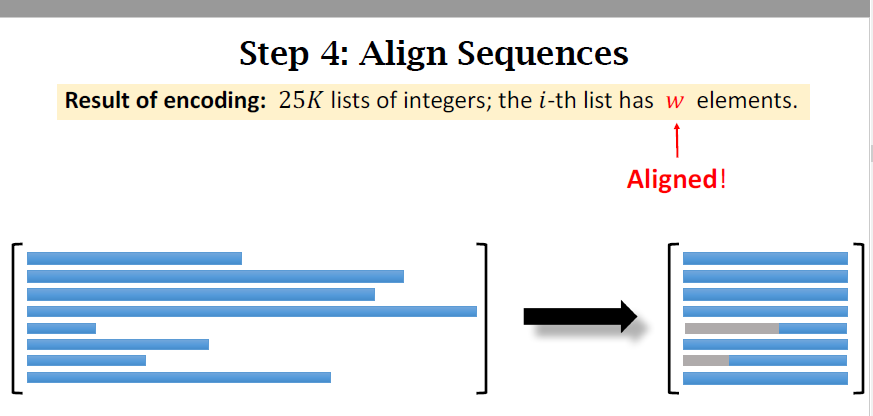
Text to Sequence
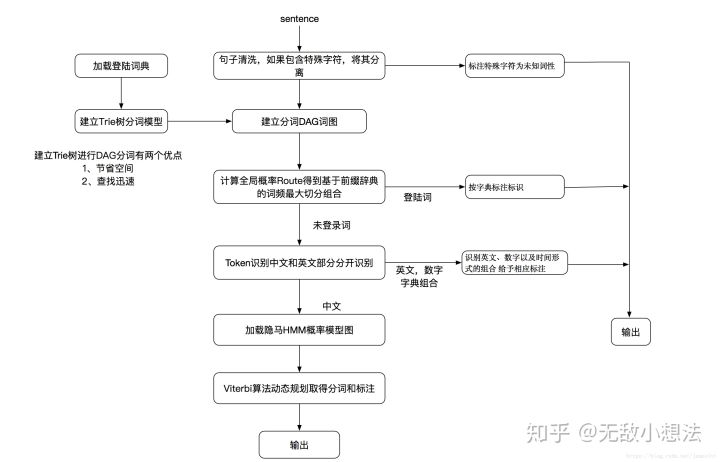
分词的算法大致分为两种:
1.基于词典的分词算法
正向最大匹配算法 逆向最大匹配算法 双向匹配分词法
2.基于统计的机器学习算法
N-gram、HMM、CRF、SVM、LSTM+CRF
jieba分词的框架图
Word Embedding
-
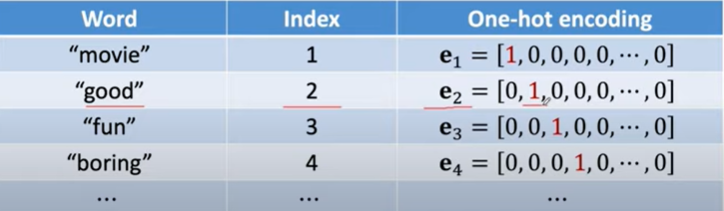
First,represent words using one-hot vectors.
-
- Suppose the dictionary contain V unique words;
- then the one-hot vectors
 are v-dimensional;
are v-dimensional;
-
second,map the one-hot vectors to low-dimensional vectors
-
- P is parameter matrix which can be learned from training data;
 is the one-hot vector of the i-th word in dictonary;
is the one-hot vector of the i-th word in dictonary;
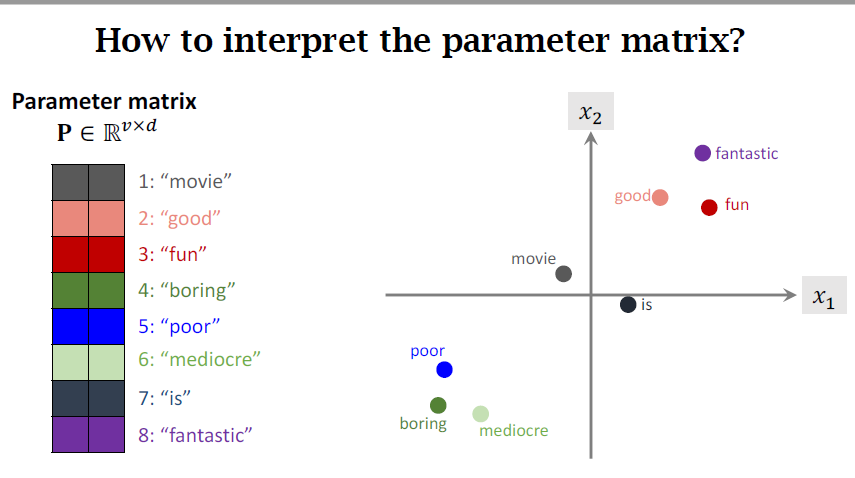
How to interpret the parameter matrix?
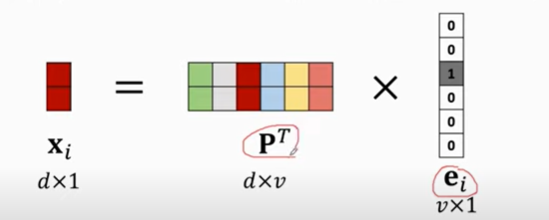
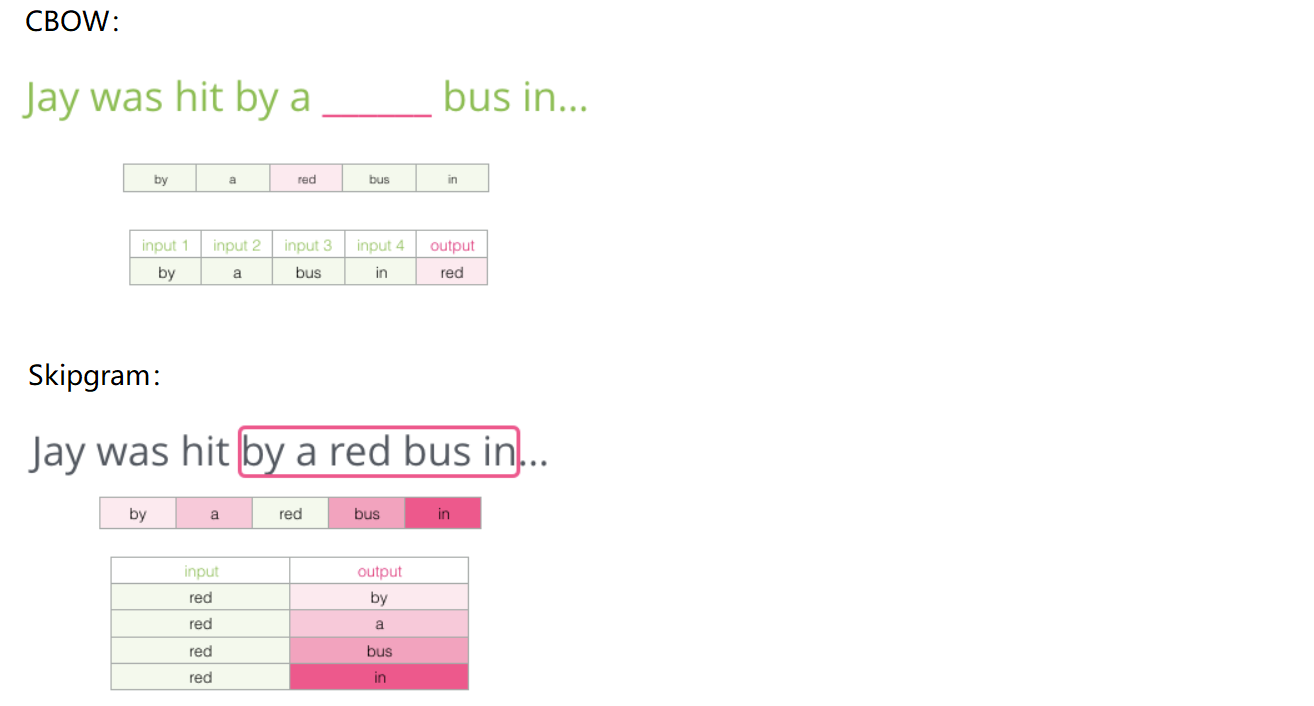
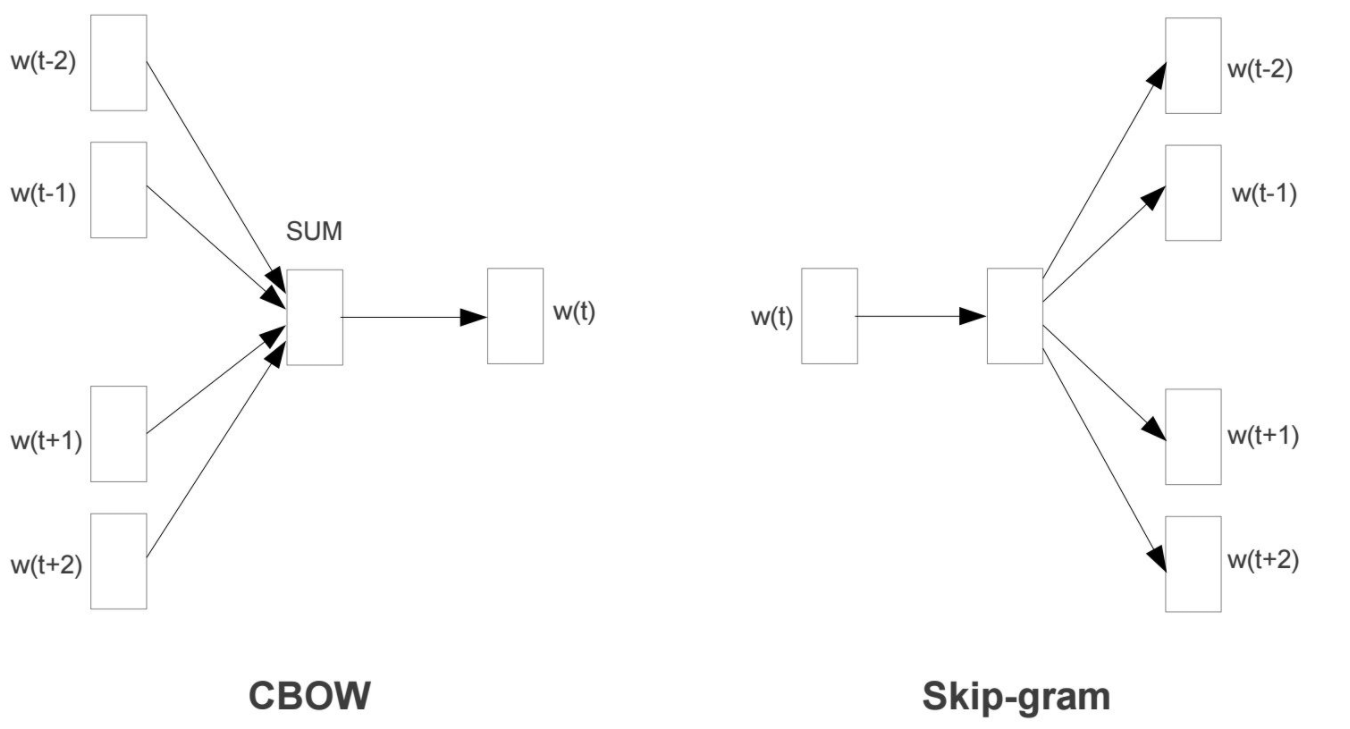
Model
无监督训练word2vec的两种模型:CBOW和skip-gram
Tip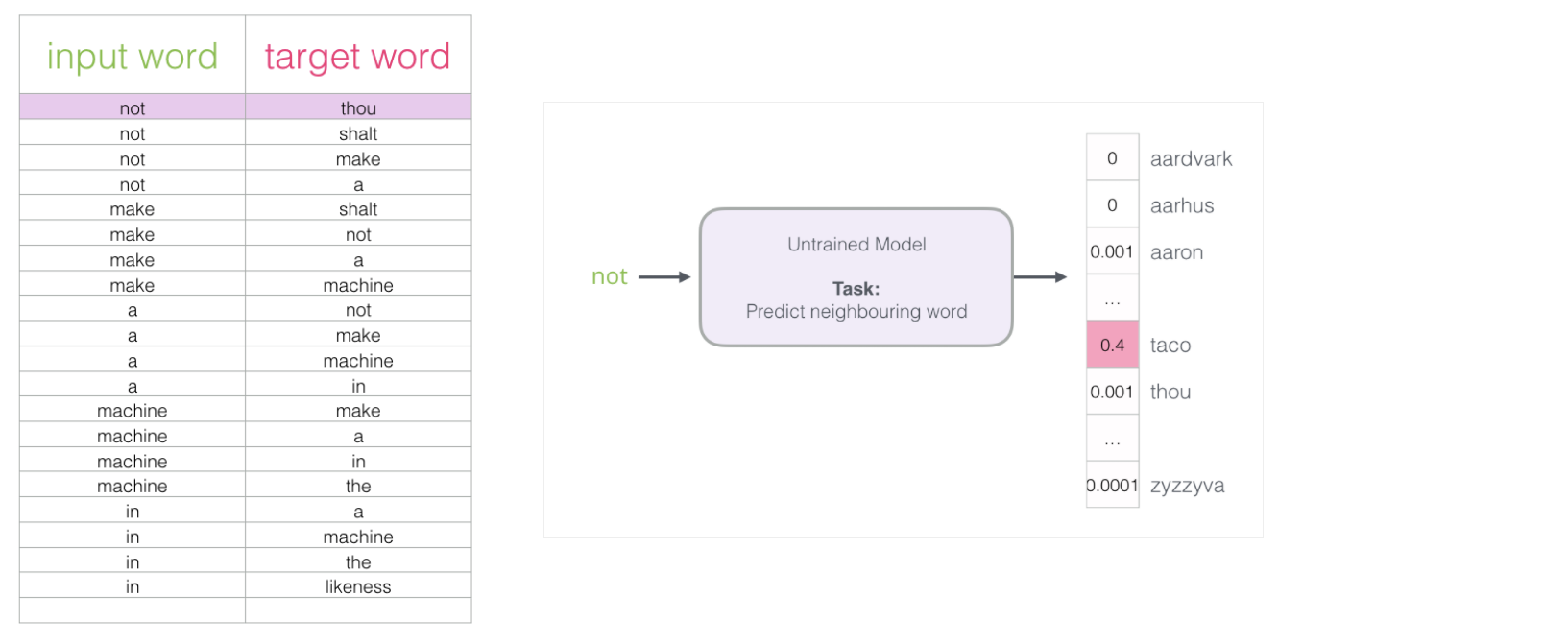
如果一个语料库稍微大一些,可能的结果简直太多了,最后一层相当于softmax,计算起来十分耗时,有什么办法来解决嘛?
- 输入两个单词,看他们是不是前后对应的输入和输出,也就相当于一个二分类任务
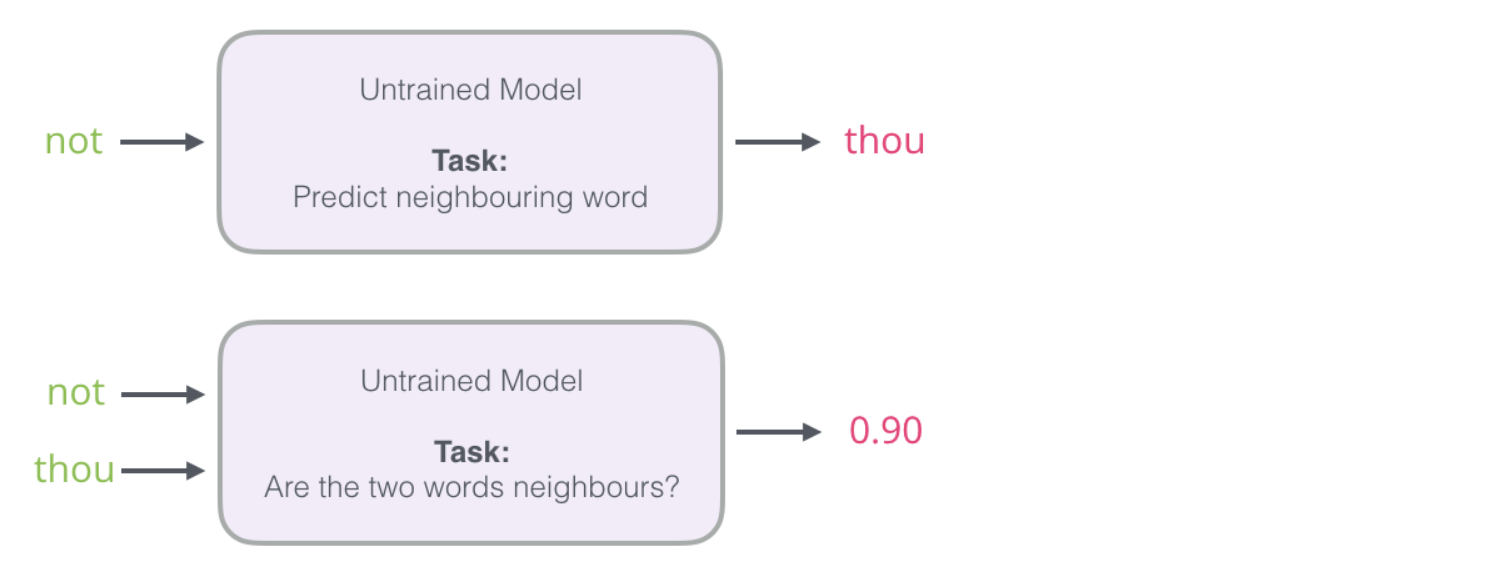
- 出发点非常好,但是此时训练集构建出来的标签全为1,无法进行较好的训练
- 改进方案:加入一些负样本(负采样模型)

Use word Classification
至此就可以尝试使用各种分类器对齐进行分类,
ShortComing
仅仅是利用词的统计和频率分类,没有考虑序列;
RNN(Recurrent Neural Networks)
using RNN to instead simple Classification
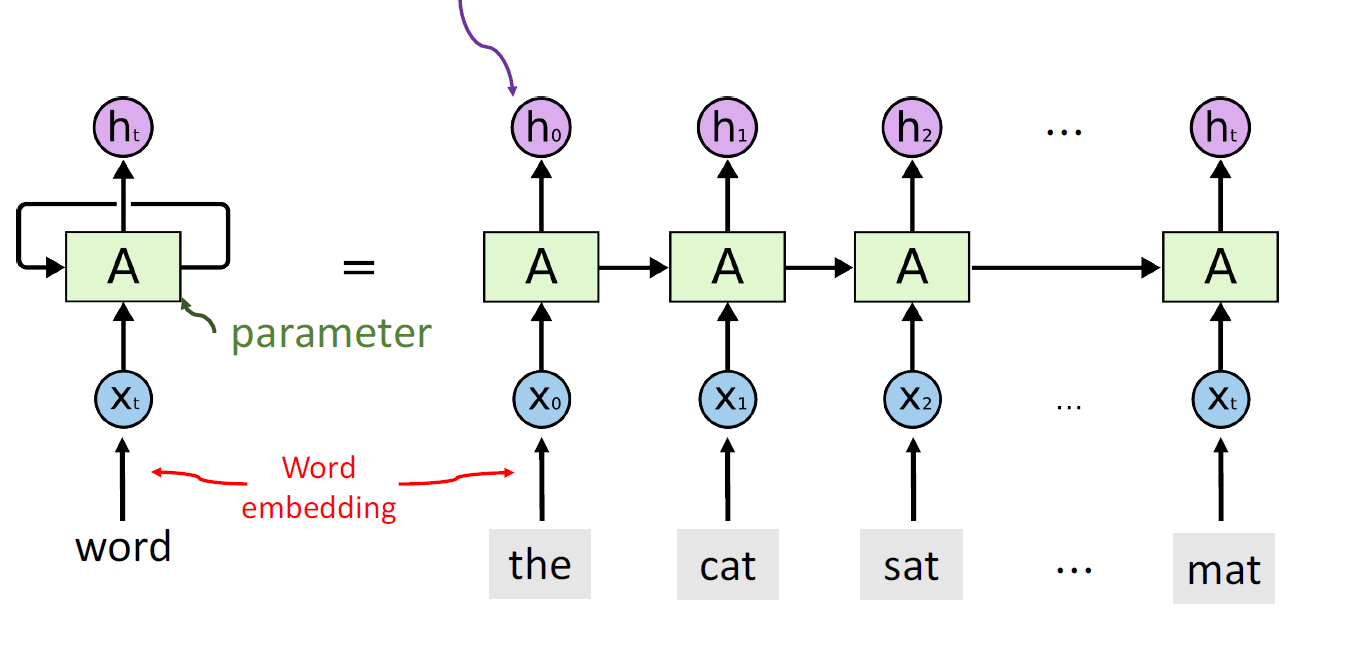
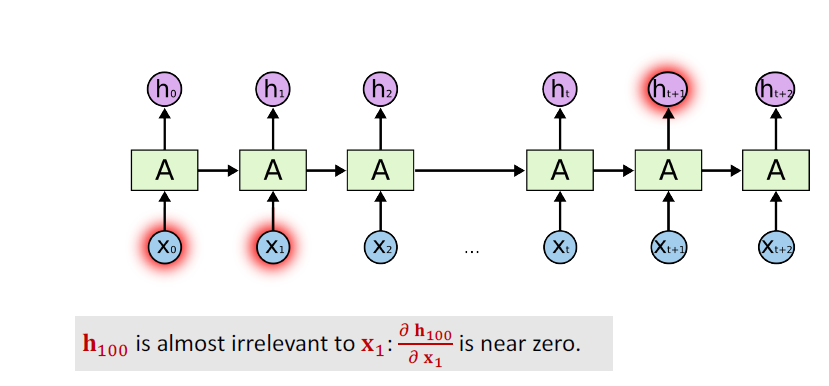
Simple RNN
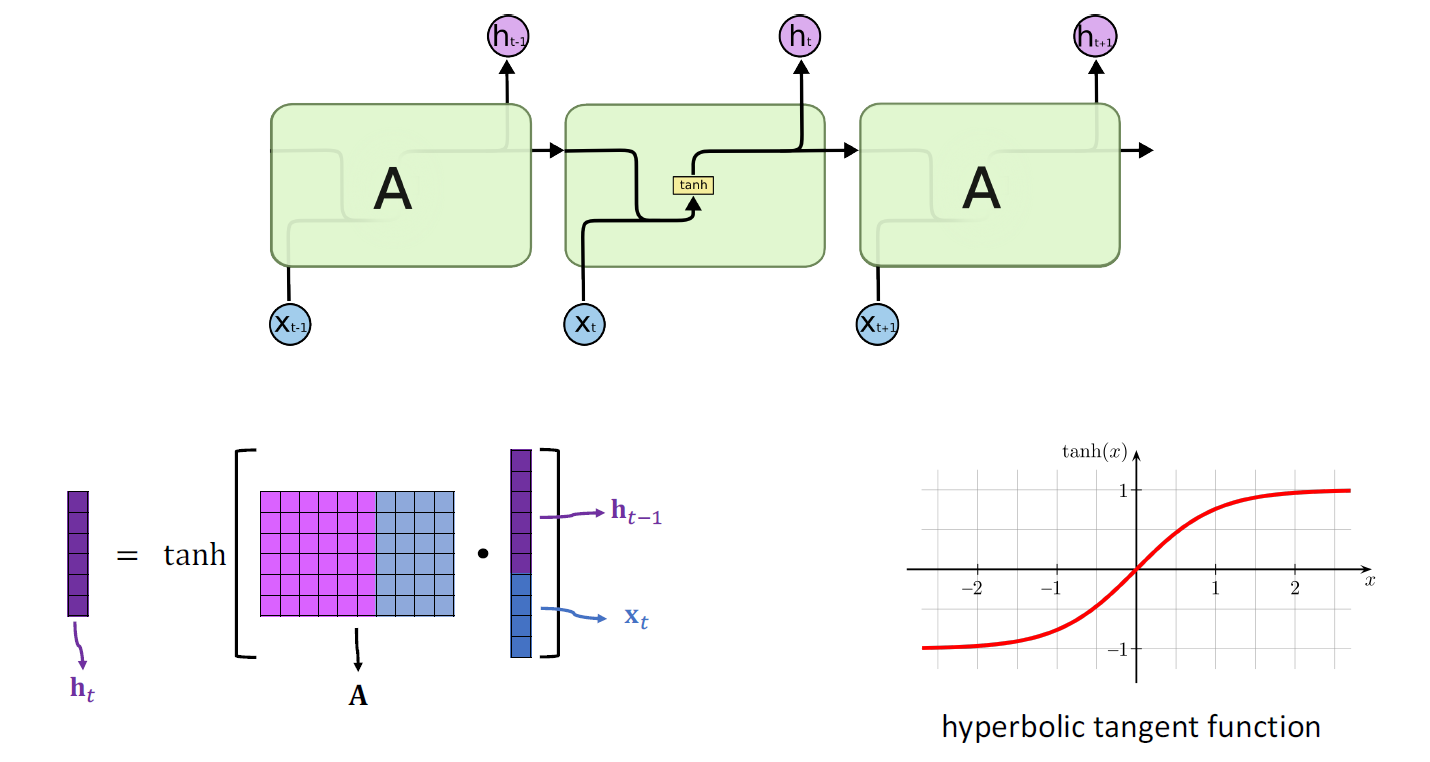
注意上述结构中的双曲正切函数是必要的,用于防止传递过程中发生的A的n次方导致后方序列失去效果!
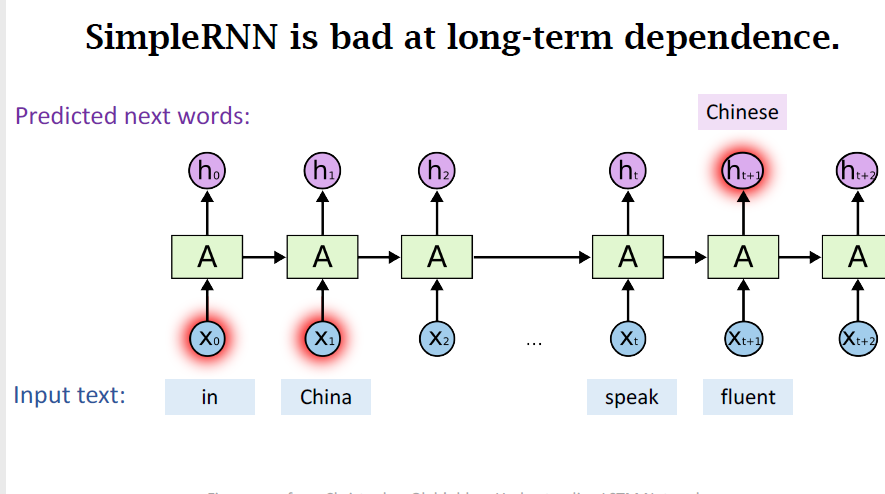
ShortComing
- SimpleRNN is good at short-term dependence;
- SimpleRNN is bad at long-term dependence;
- Only one such parameter matrix,no matter how long the sequence is;
LSTM Model(Using LSTM instead Simple RNN)
Hochreiter and Schmidhuber. Long short-term memory. Neural computation, 1997.
- Conveyor belt: the past information directly flows to the future.(解决梯度消失)
- Each of the following blocks has a parameter matrix:
-
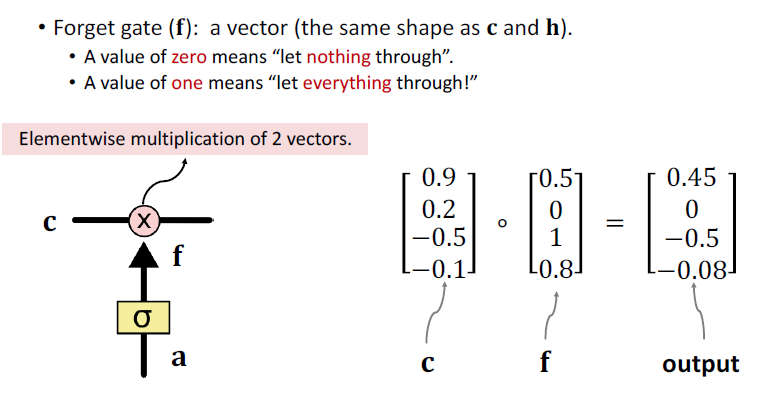
- Forget gate**😗*forget the gender of the old subject.
- Input gate:decides which values of the conveyor belt we’ll update.
- New value (
 ): to be added to the conveyor belt
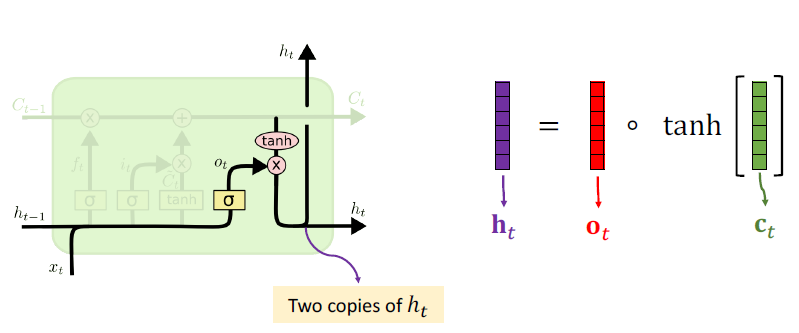
): to be added to the conveyor belt - Output gate**😗*decide what flows from the conveyor belt
 to the state
to the state  .
.
- Number of parameters:
- 4 * shape(h) * [shape(h) + shape(x)]
Gate Struct
Update
RNN More Effective
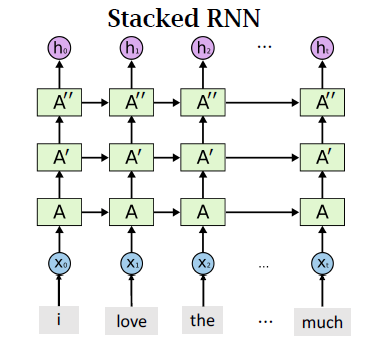
Stacked RNN
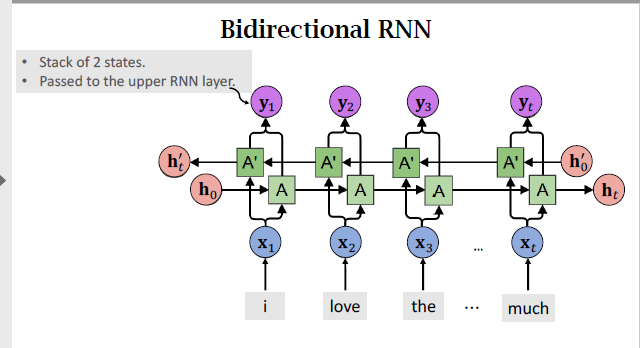
Bidirectional RNN
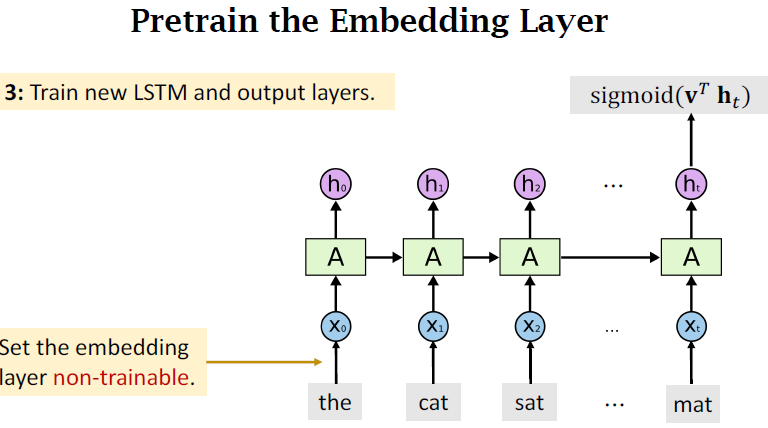
Pretraining
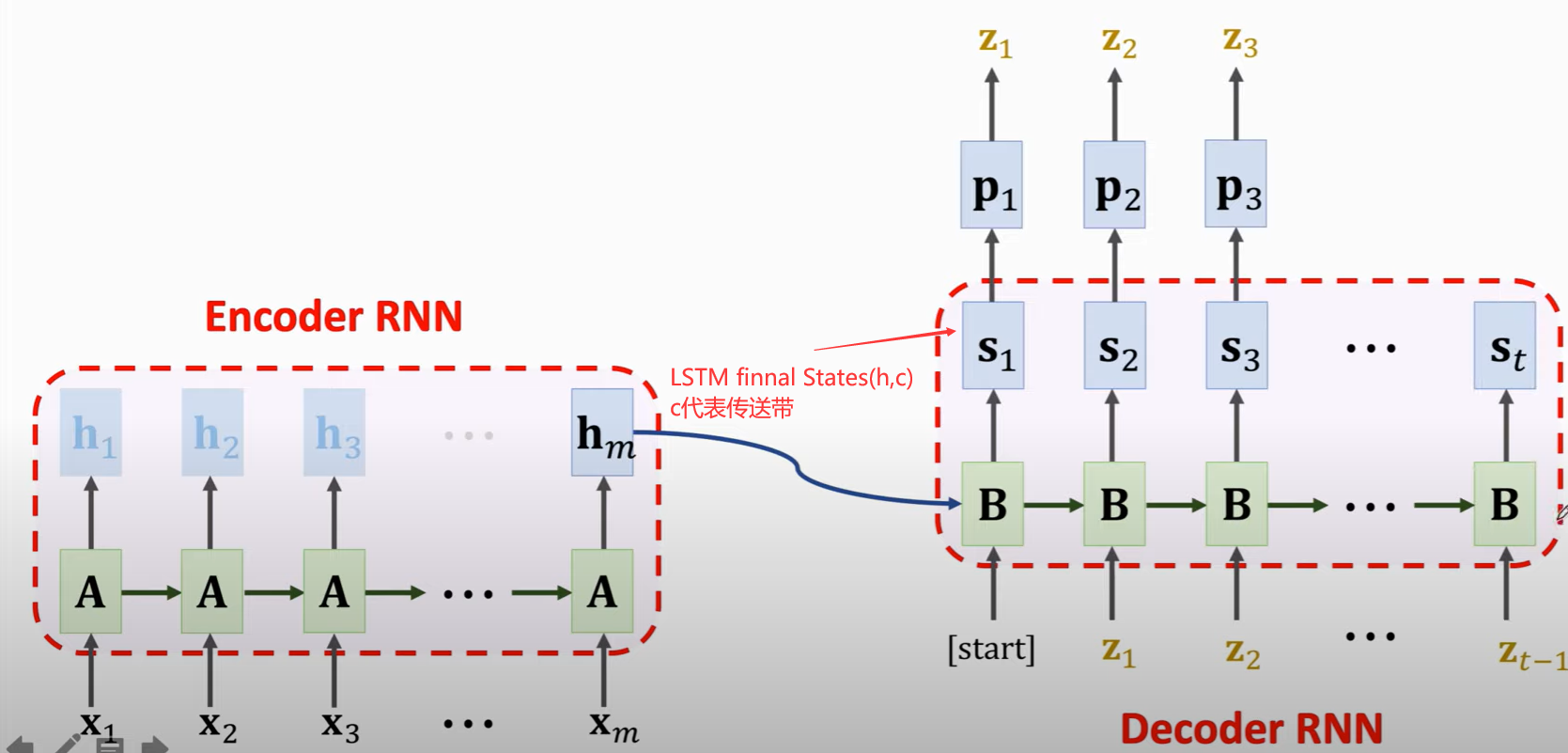
Seq2Seq
How to Improve?
- Bi-LSTM instead of LSTM;(Encoder ONLY!)
- Tokenization in the word-level(instead of char-level);
- Multitask learning;
- Attention
Attention
Bahdanau,Cho,& Bengio. Neural machine translation by jointly learning to align and translate. In ICLR, 2015.
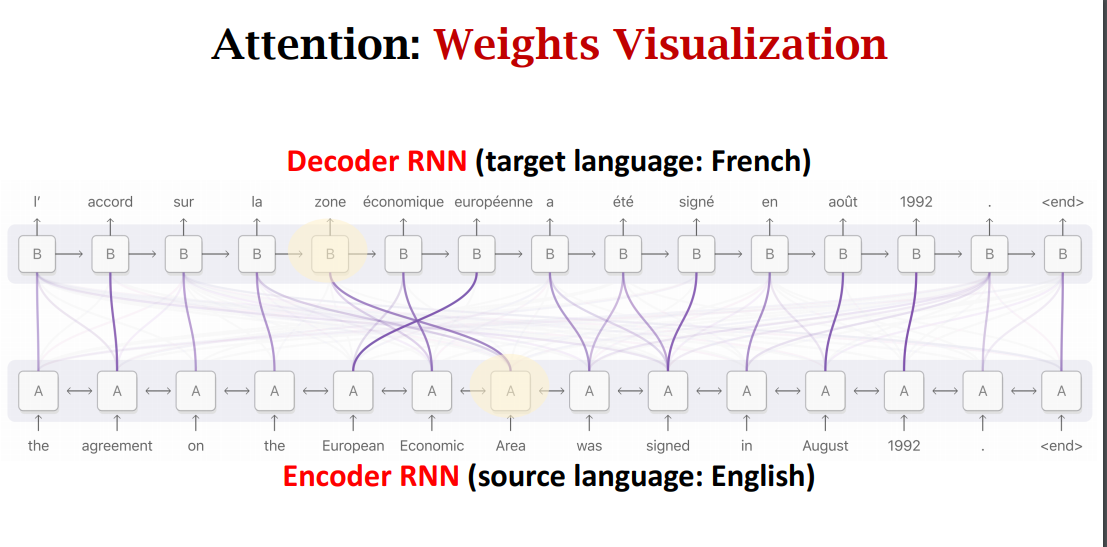
- Attention tremendously improves Seq2Seq model.
- With attention, Seq2Seq model does not forget source input.
- With attention, the decoder knows where to focus.
- Downside: much more computation.
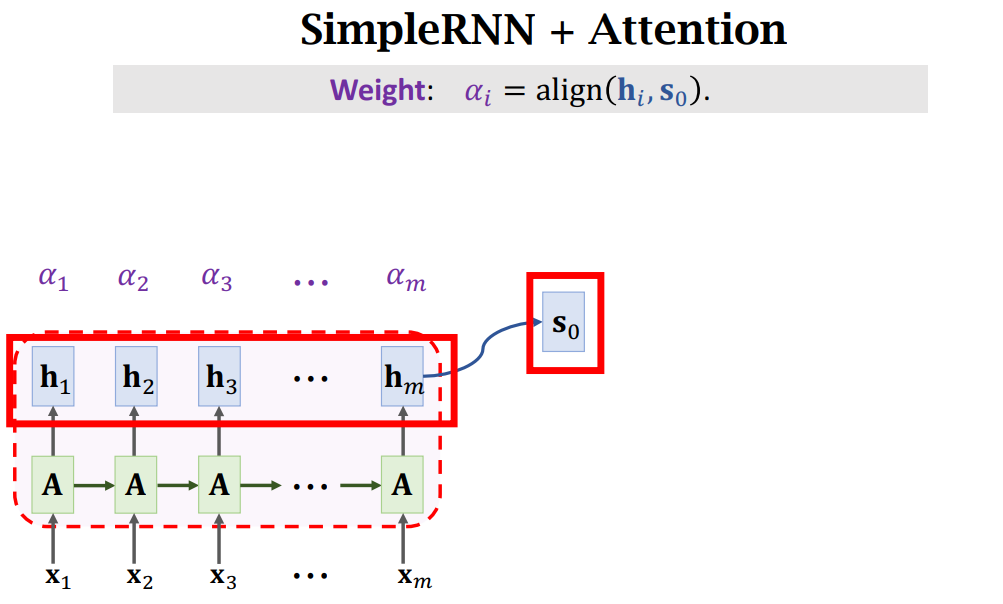
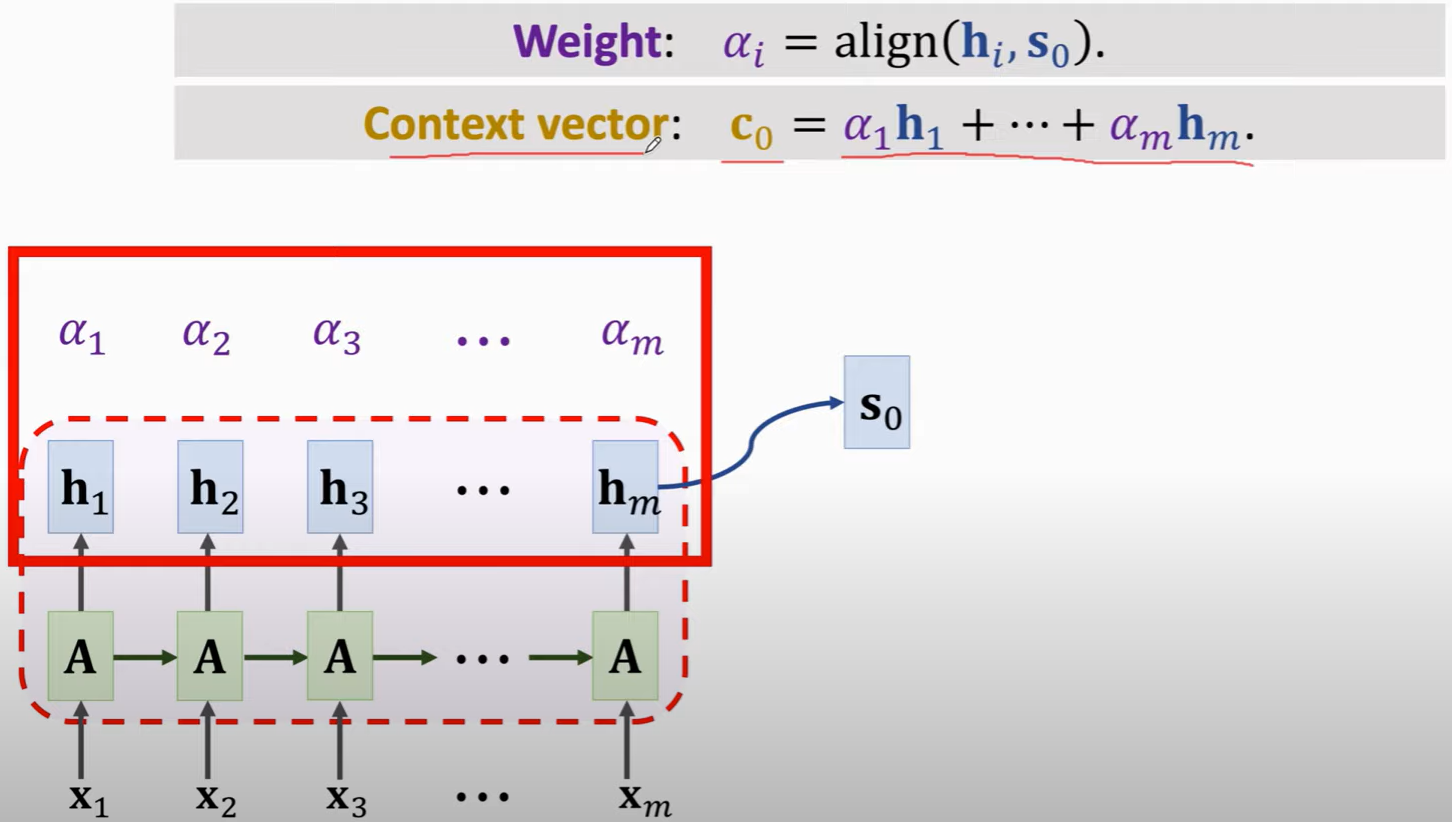
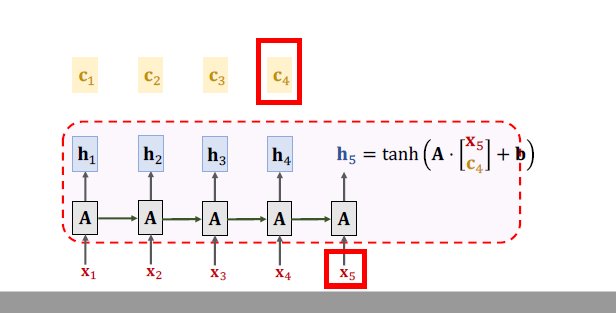
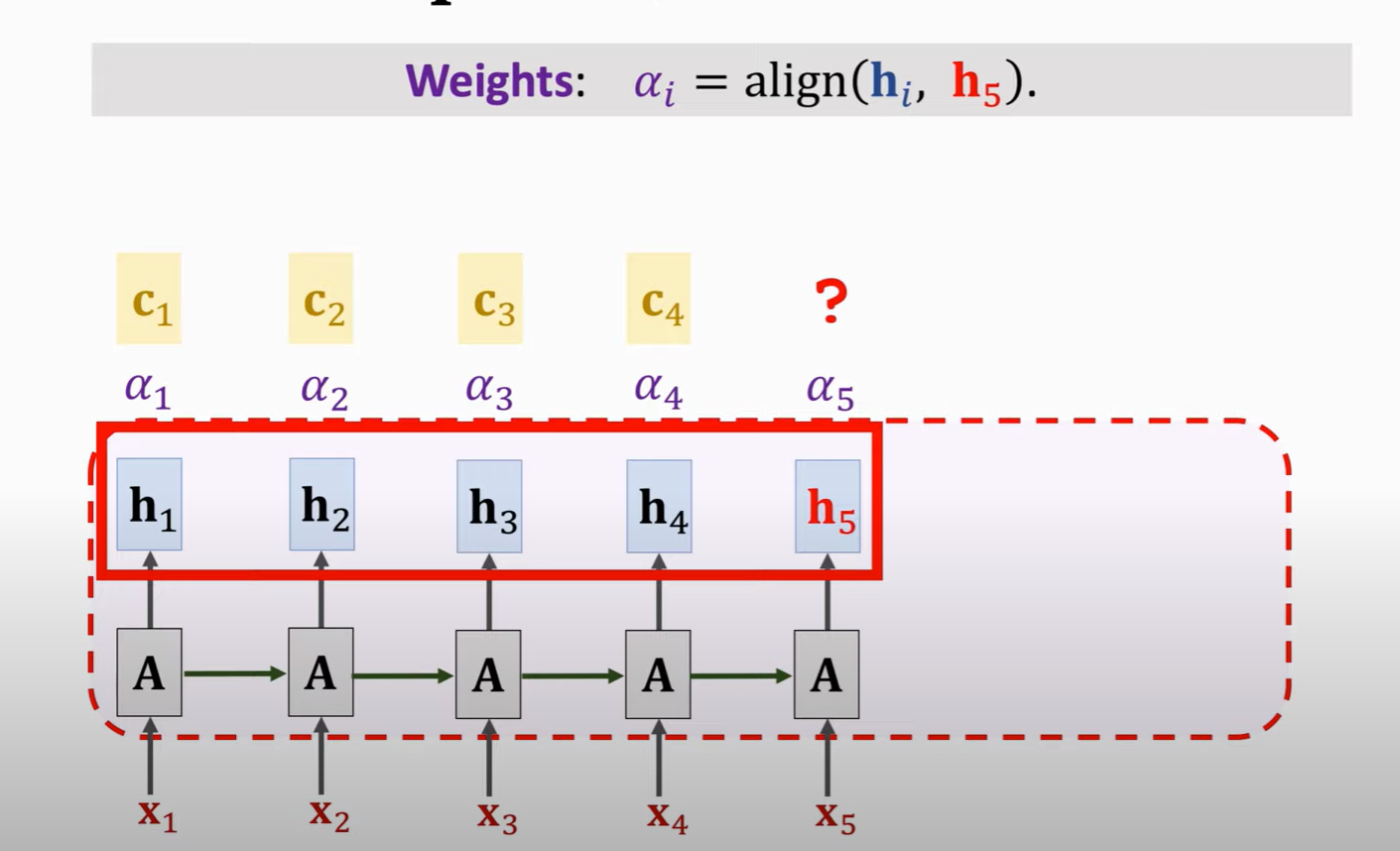
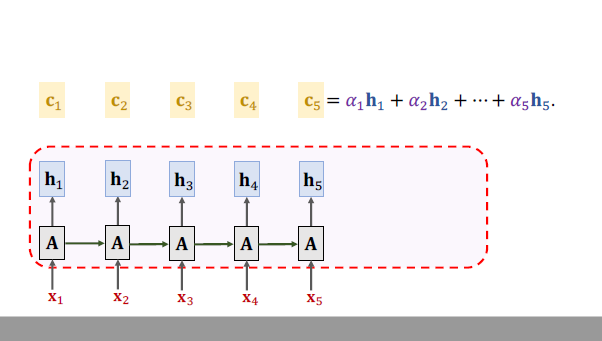
Much ways to calculate Weight:
 **
**
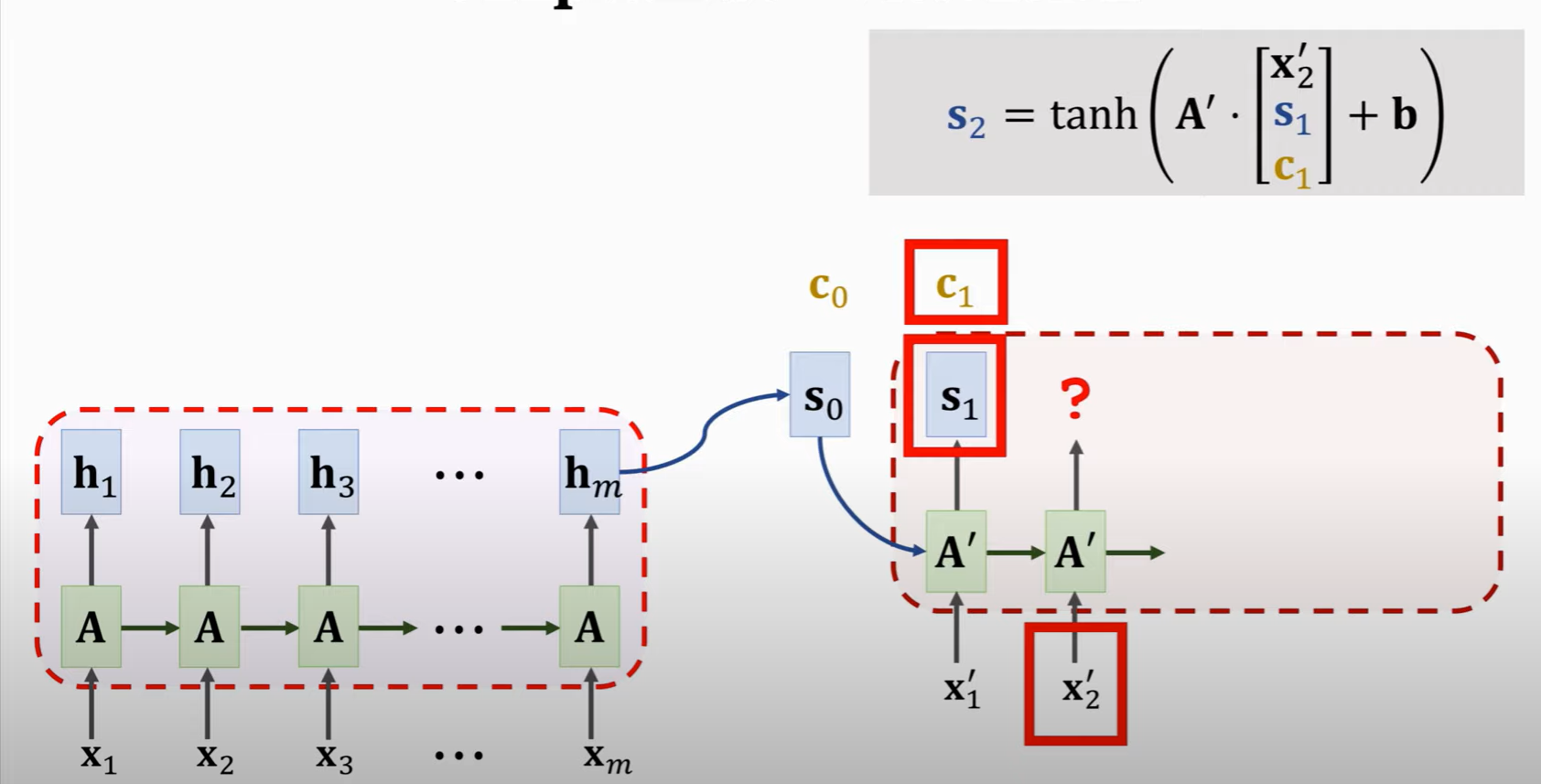
 **
**
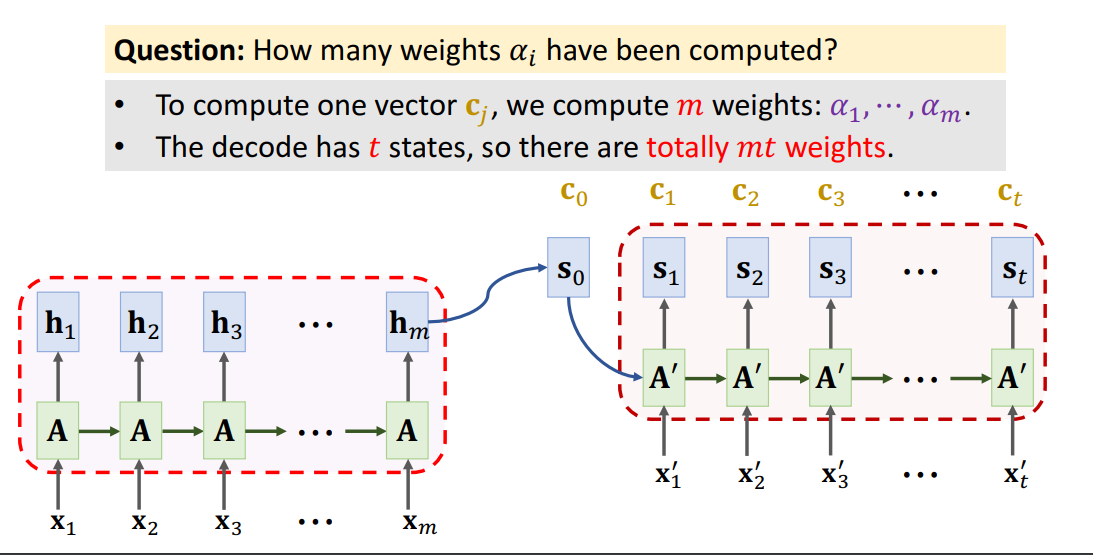
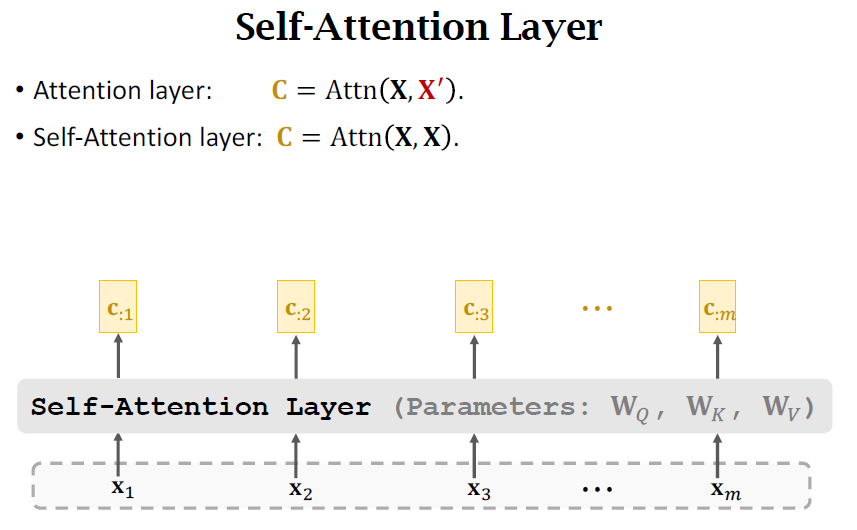
Self-Attention
通用性更强,跳出了seq to seq 的局限;

Attention to seq2seq

Transformer
- Bahdanau, Cho, & Bengio. Neural machine translation by jointly learning to align and
translate. In ICLR, 2015.- Cheng, Dong, & Lapata. Long Short-Term Memory-Networks for Machine Reading. In
EMNLP, 2016.- Vaswani et al. Attention Is All You Need**. In NIPS, 2017.**
- Transformer is a Seq2Seq model.
- Transformer is not RNN.
- Purely based attention and dense layers.
- Higher accuracy than RNNs on large datasets.
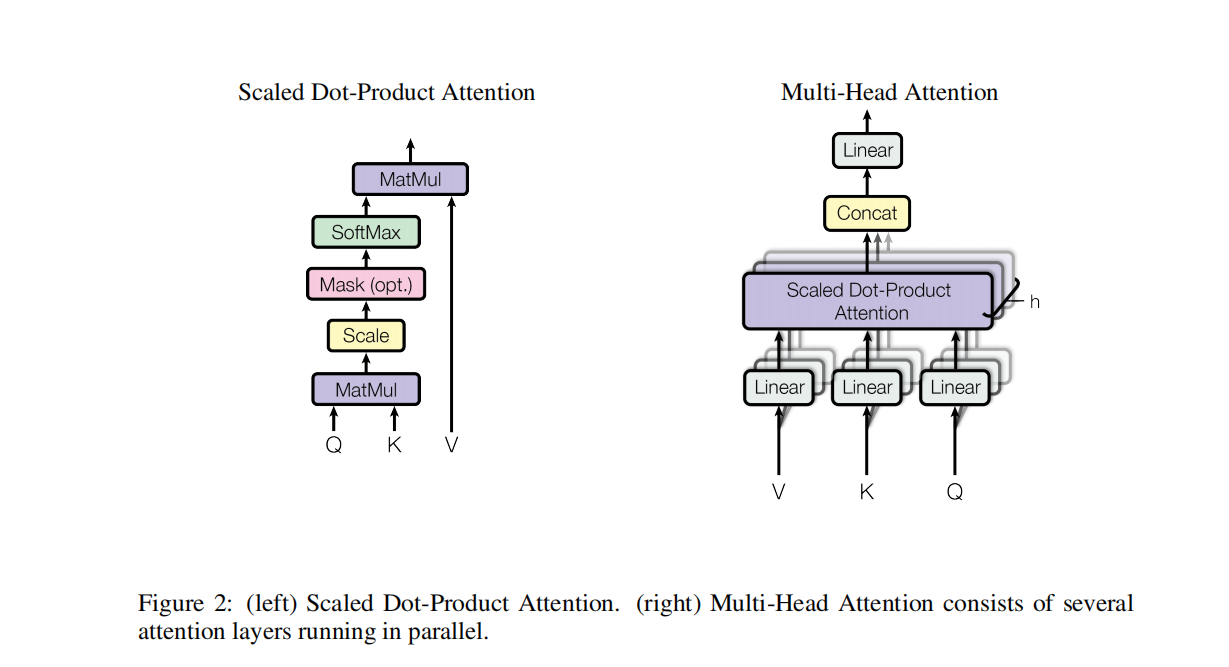
Attention without RNN
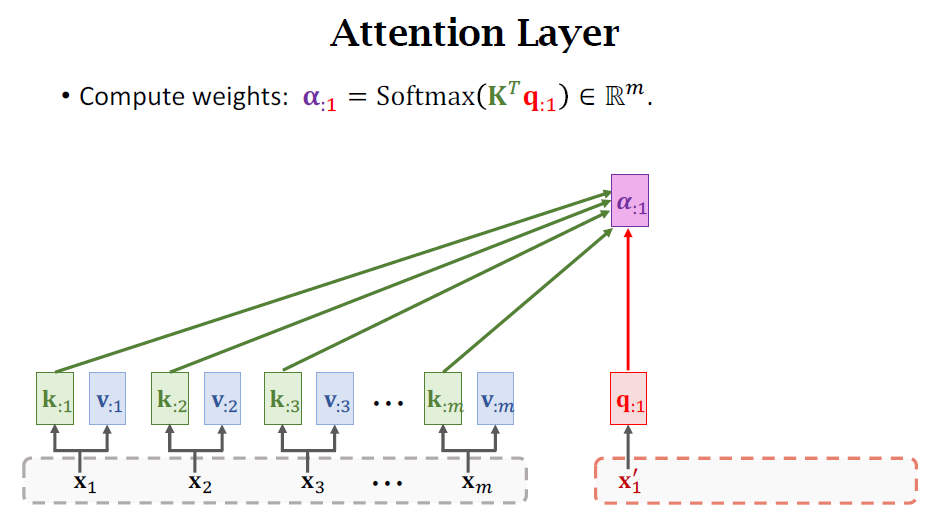
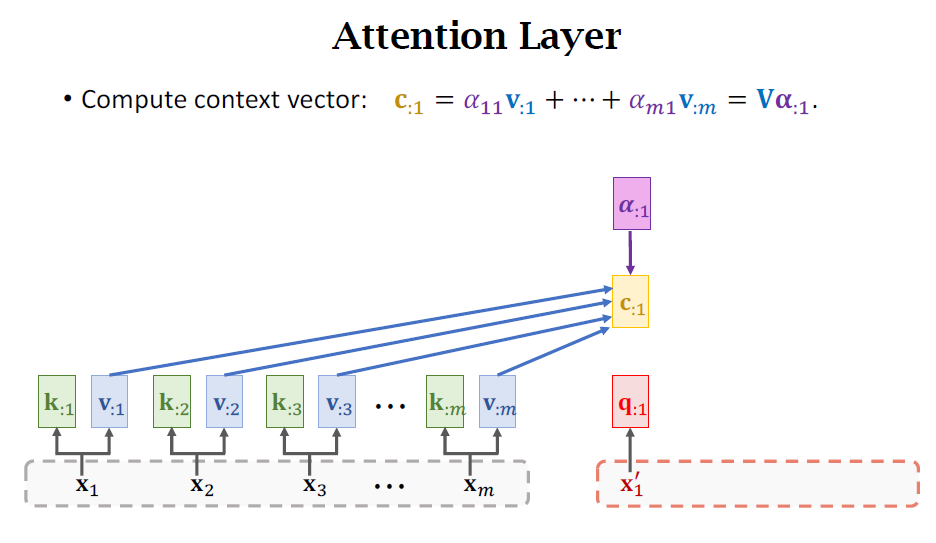
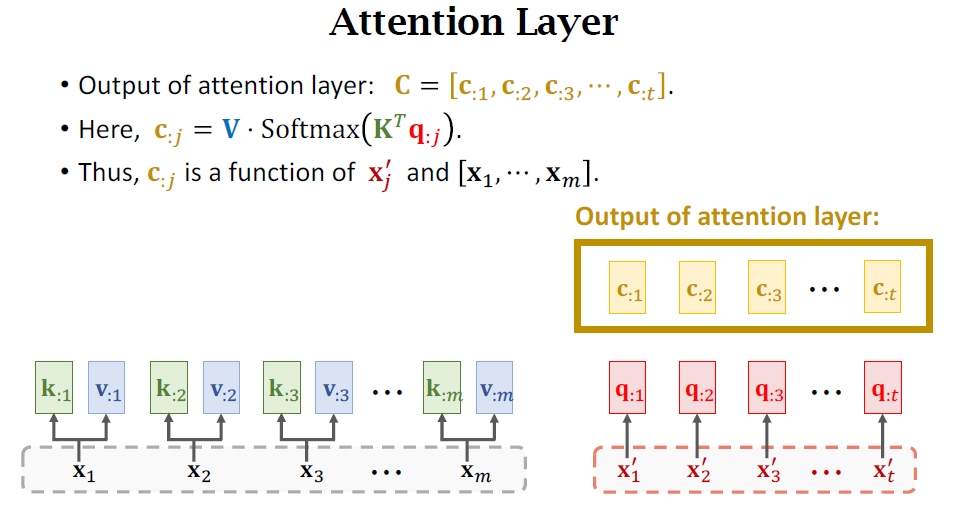
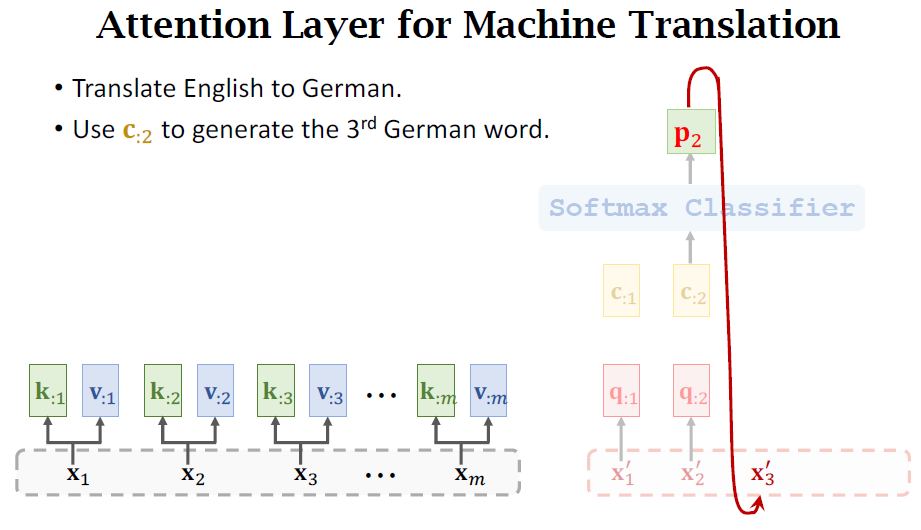

Self-Attention without RNN
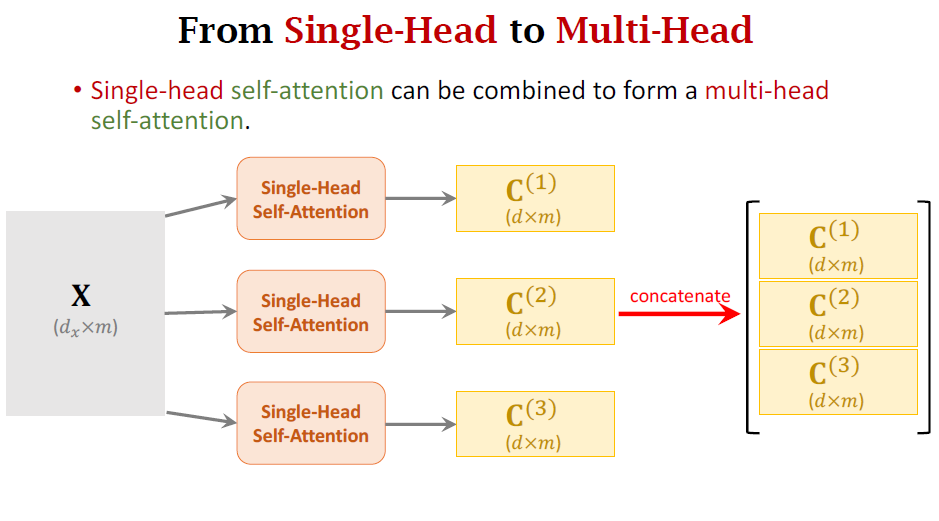
Transformer
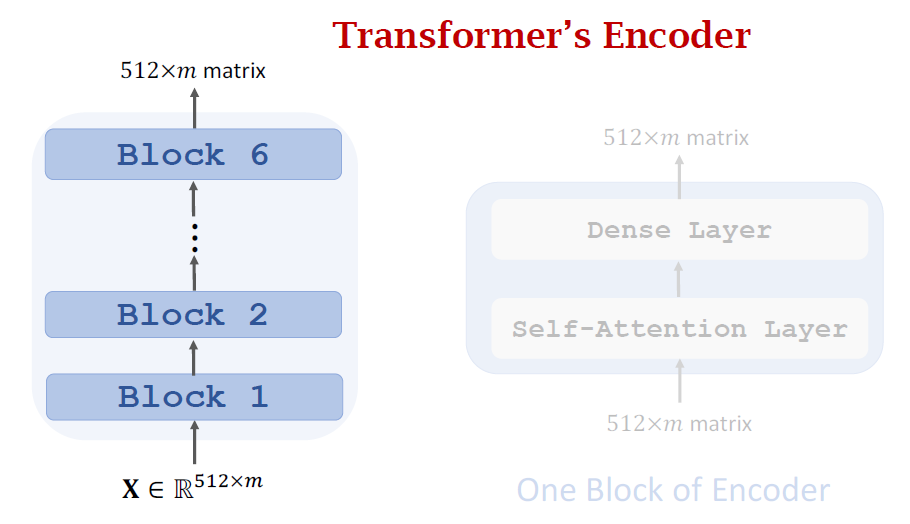
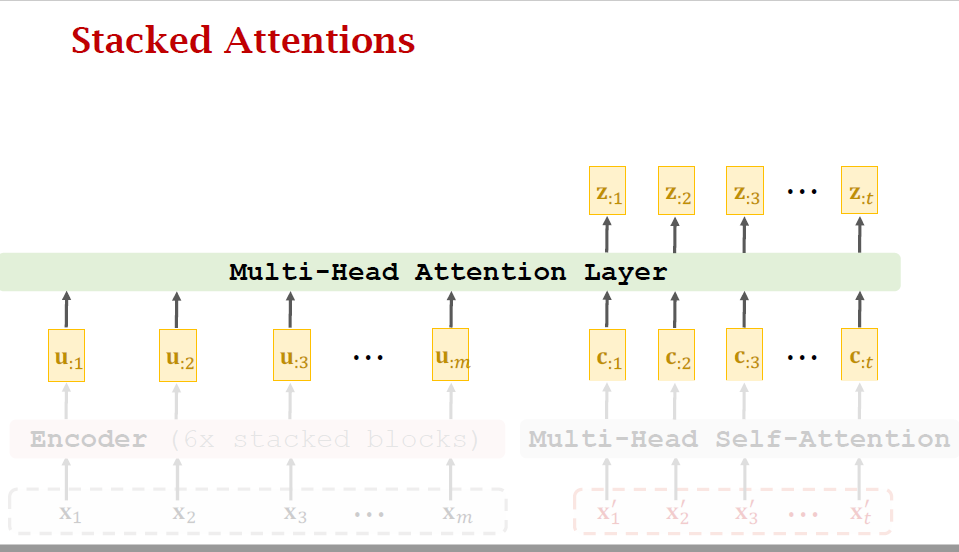
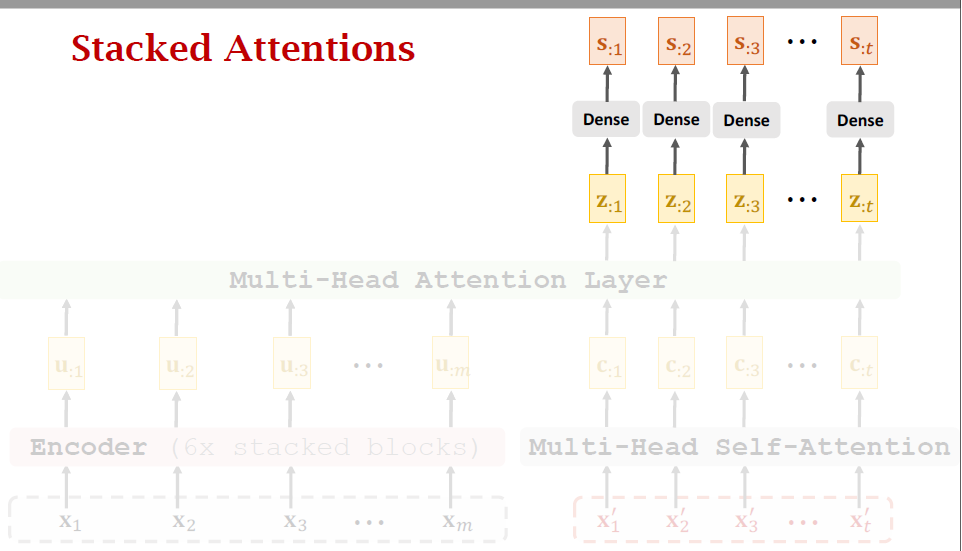
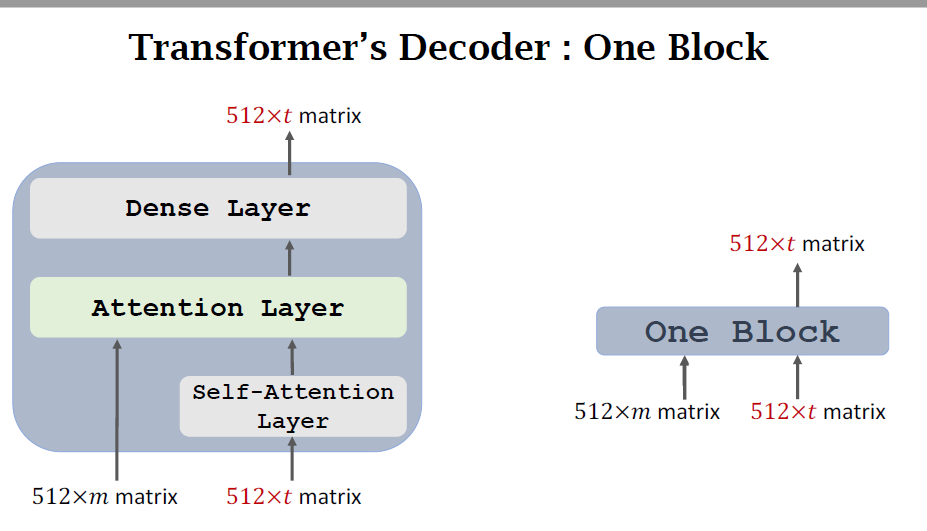
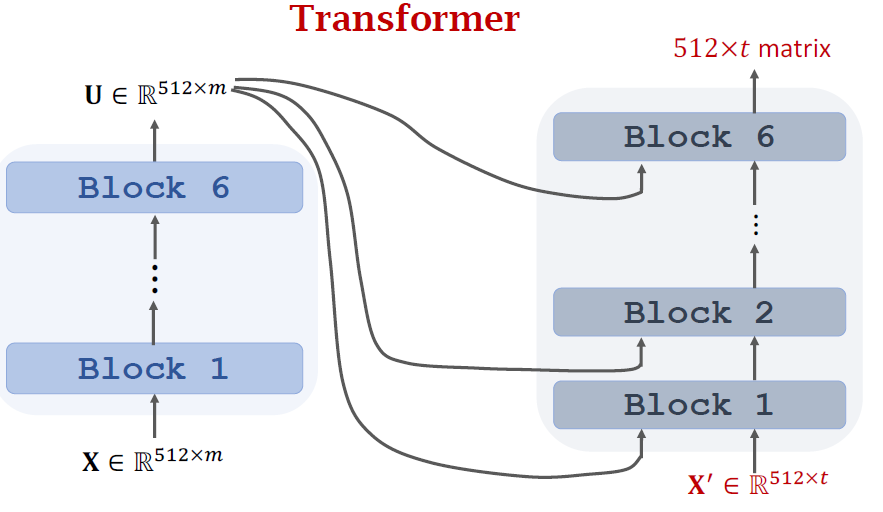
- Transformer is Seq2Seq model; it has an encoder and a decoder.
- Transformer model is not RNN.
- Transformer is based on attention and self-attention.
- Transformer outperforms all the state-of-the-art RNN models.
BERT(Bidirectional Encoder Representationsfrom Transformers)
Devlin, Chang, Lee, and Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In ACL, 2019.
Vaswani and others. Attention is all you need. In NIPS, 2017.
Main:
- Predict masked word.
- Predict next sentence.
Combining the two methods
- Loss 1 is for binary classification (i.e., predicting the nextsentence.)
- Loss 2 and Loss 3 are for multi-class classification (i.e., predicting the masked words.)
- Objective function is the sum of the three loss functions.
- Update model parameters by performing one gradient descent.
Data
- BERT does not need manually labeled data. (Nice! Manual labeling is expensive.)
- Use large-scale data, e.g., English Wikipedia (2.5 billion words.)
- Randomly mask words (with some tricks.)
- 50% of the next sentences are real. (The other 50% are fake.)

