Anthropic Engieering Docs 笔记
心得/总结
| 热词 | 动机 | 注意力 | 痛点/趋势 |
|---|---|---|---|
| prompt工程 | 做聊天机器人 | 准确解决问题 | |
| context工程 | 做系统工程 | 多数据源融合 |
|
| harness工程 | 做软件工程 | 可观测性/迭代 |
- 任何事如果人/专家无法清晰解决,也不要指望LLM/agent可以搞定
- 所以产物都是源于真实需求的沉淀
- 务实
- 对LLM足够了解
- 营销/宣传能力很强
Building effective agents
- 快速验证 (框架不总是捷径,要快到学习框架成本也抛弃)
- vibe-coding时代,其实用不用框架也不那么重要
- 分析需求,对于固定流程的,直接上workflow,仅当流程完全可不控,才进行Agent设计
- 对于agent,建议直接从API开始,从框架开始容易陷入过度设计
- llm/workflow/agent 选择也是在权衡效率和精度
- LLM/传统分类模型都是workflow中router的好选择
- 困难或无法预测步骤的开放式问题比较适合设计agent,其也必然涉及多轮人类参与和决策
- 选择Agent就意味着面对沙盒、成本、安全等问题
Effective context engineering for AI agents
判断LLM工程化的机会的核心是了解LLM,了解其特点和能力边界,才能定位需要工程化的点
- LLM搞不定,深入研究探索
- LLM能搞定,先简单粗暴,等LLM升级
上下文窗长(算法和硬件驱动)当前发展可以参考历史上内存(摩尔定律驱动)
- 短期内会有很多奇技淫巧
- 可预见性的这些奇技淫会有较长的生命力
动机
- transformer&attention的特性必然会导致长上下文资源受限
- 长上下文训练数据的缺失
方案
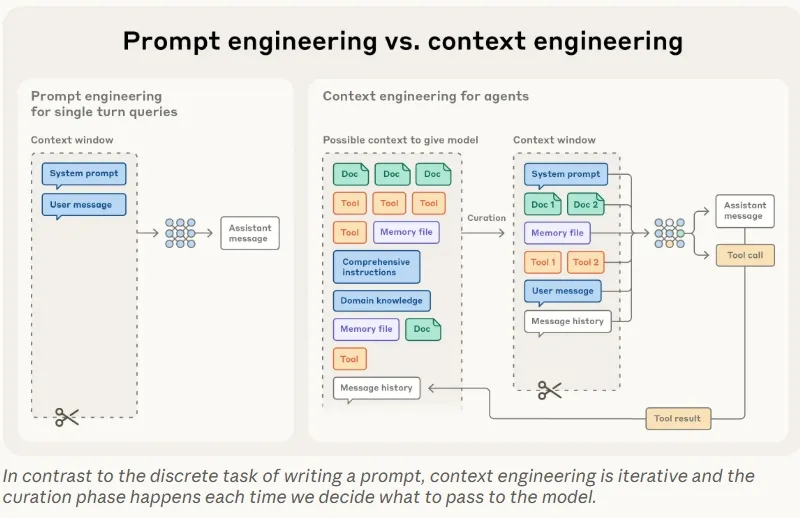
静态上下文
静态上下文的组织原则是 高信息量、紧凑、精心设计
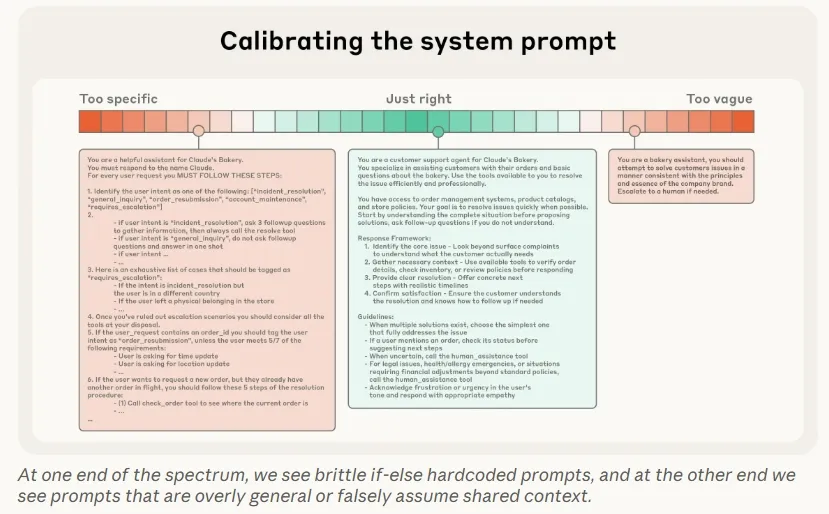
- System prompt 需要在具体和粗略间寻找平衡,建议采用结构化并采用section划分结构
- 工具定义参考编程中的函数设计规范即可,工具集合建议选择最小化、最有价值的集合
- 举例是一个对LLM有效的方案,建议多举正例,不要过多枚举边缘用例
动态上下文
装入元信息运行时展开和静态装入需要在效率和成本间权衡 压缩的核心是保留有效信息
- 可以借助LLM做摘要
- 建议从追求召回率逐步到追求精度
- 工具结果通常是可以安全丢弃的
结构化笔记/临时记忆 移出上下文并落盘,在需要时召回(类比随手笔记)
另外多智能体架构也为突破窗长提供了思路,即分治
Beyond permission prompts: making Claude Code more secure and autonomous
组合高级接口/特性,针对痛点优化
动机
- 代码执行存在安全风险
- human-in-loop权限设计影响效率和用户体验
方案
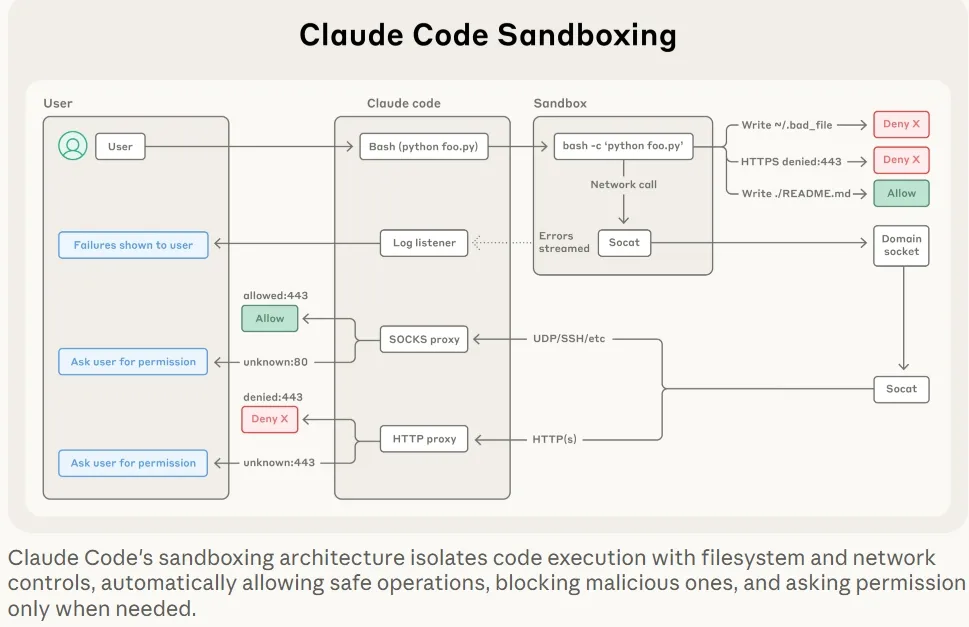
基于os特性构建沙盒(文件隔离 和 网络隔离-代理)
引入新的沙盒运行时,无需额外创建和容器的开销,允许精确指定tool/agent/mcp的 文件目录和网络主机访问权限
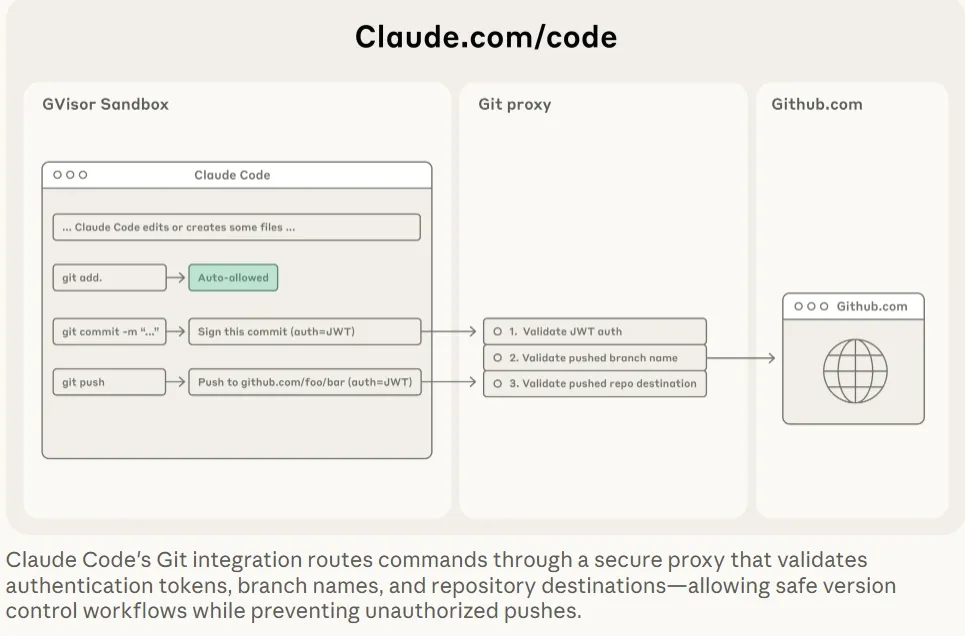
Claude Code on the web
一次会话一个沙盒
Code execution with MCP: Building more efficient agents
Agent也是软件,也符合软件工程,很多困难直接从传统软工/方案中抄
Grep/bash/cat/fileSystem…
动机
mcp工具太多
- 工具定义消耗上下文
- 工具执行临时结果污染上下文
方案
将MCP Server的工具当作代码API而不是function call。
核心思路,
- LLM擅长写代码,而非常规人类任务
- LLM擅长应对文件系统
一种方式是将实现为文件树,然后让agent以文件系统结构来了解和采用工具
// 一个工具一个文件
servers
├── google-drive
│ ├── getDocument.ts
│ ├── ... (other tools)
│ └── index.ts
├── salesforce
│ ├── updateRecord.ts
│ ├── ... (other tools)
│ └── index.ts
└── ... (other servers)- 渐进式揭漏(解决mcp工具信息爆炸)
- 工具结果在上下文中利用率更高
- 更强的控制流
- 降低模型决策带来的延迟
- 更容易实现隐私保护(解决mcp安全风险)
- 方便基于文件系统做 状态持久化/trace 等
- 写出工具调用代码可复用->甚至形成skills
成本:该方案对infra有一定要求:沙盒、资源限制、监控
Introducing advanced tool use on the Claude Developer Platform
正经技术团队,考虑的永远是能不能实现的需求,而不是合不合理的需求
(140k定义的工具,Anthropic考虑的是怎么实现,而不是需求是否合理)
新特性
| 特性 | 挑战 | 思路 | 方案 |
|---|---|---|---|
| Tool Search Tool |
| 渐进式展开粗排+精排 | 新增工具的用于搜索工具(regex,bm25) |
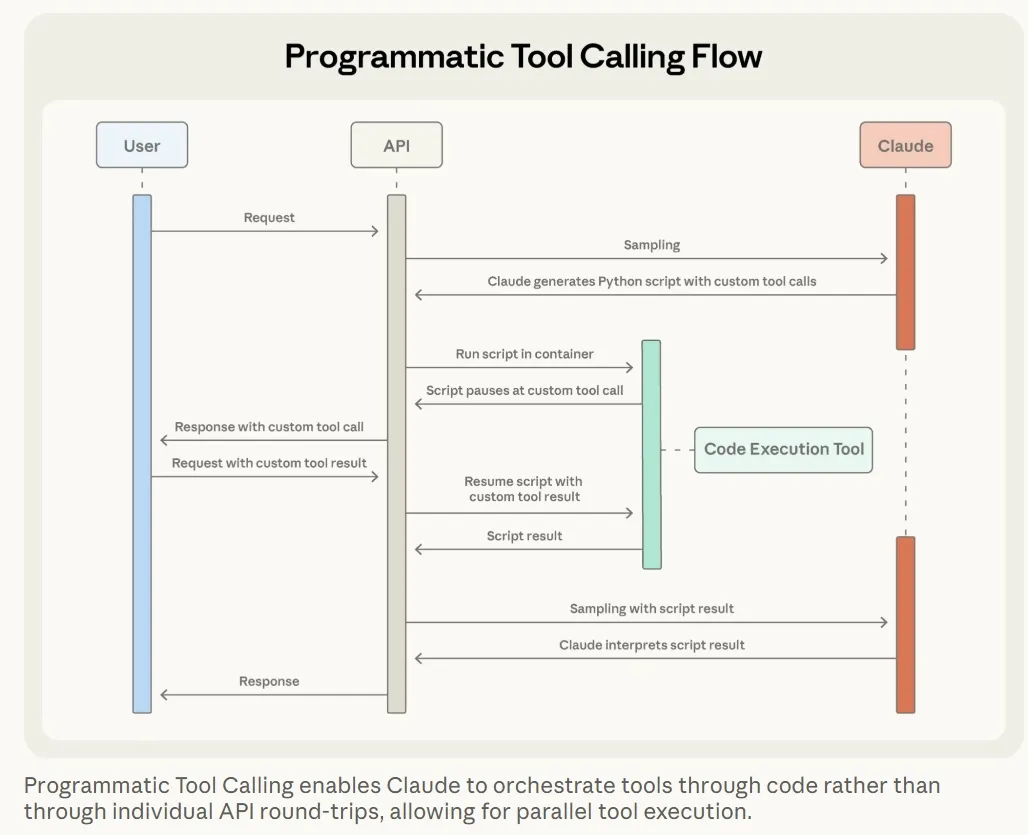
| Programmatic Tool Calling |
| 硬逻辑问题代码优于LLM | 工具封装成函数,LLM-coding设计调度逻辑 |
| Tool User Examples | json Schema仅验证格式,复杂参数很难引导模型正确调用 | 示例优于定义 Prompt工程 | 补充调用示例 |
最佳实践
- 从Agent当前瓶颈开始,选择你所需的特性
- Tool Search Tool
- 选择3-5个频繁工具常驻
- 将tool-search-tool支持工具的范围装入systemPrompt便于模型搜索
- 清晰的命名和定义其他工具
- Programmatic Tool Calling
- 支持编程调用的工具,应文档化说明工具结果,方便coding解析
- 设置可选的工具属性,幂等、并行等
- Tool Use Examples
- 重点完善schema不足与描述的场景
- 展示真实数据
- 展示多种用法
Demystifying Evals for AI agents
重 产品/模型/数据,轻工程
动机
挑战一:多轮agent执行结果更复杂
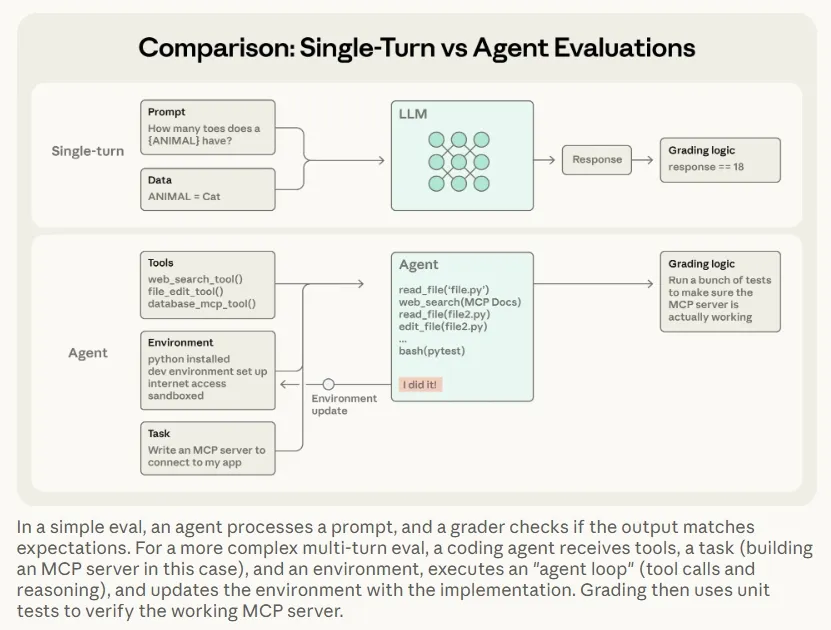
挑战二:前沿模型做出超越静态标准答案的更优解
为什么评价很重要?
在原型阶段,没有完整评估也能正常工作。但当其进入产品阶段/规划化,没有标准测试将会带来问题。
- 迭代失控(完全依赖客户反馈)
- 无法区分正常的功能退化和噪音
- 统一预期标准
- 加速开发过程
- 快速接入新模型
- 降低产品和研发的沟通成本
最佳实践
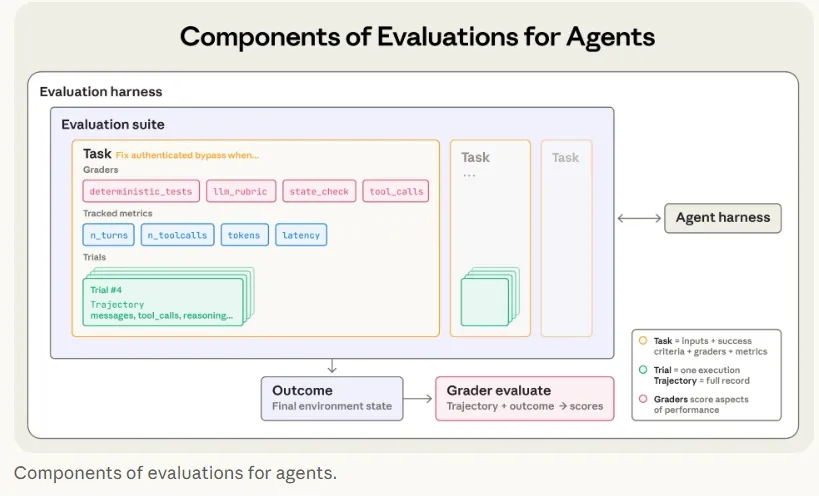
三类评价常见的评价器,及其特点
- 基于代码的评价器
- 基于LLM的评价器
- 基于人力的评价器
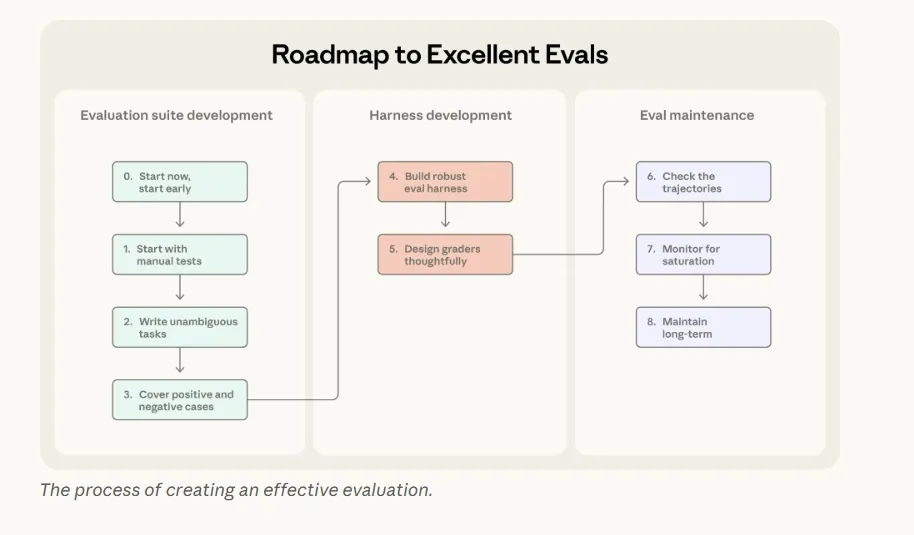
- 收集最初评估集
- 尽早开始构建,不用过多和完善,相信28定律
- 开发过程中首次测试就可以开始构建评估集
- 编写无歧义的任务,并提供参考解决方案
- 数据集要均衡(即各类case分布合适)
- 设计评价harness和评价器
- 用稳定环境构建鲁棒/隔离的评价harness
- 精心设计评分器
- 尽量使用确定性评分器
- 需要更高灵活时采用LLM评分器
- LLM-as-a-judge要与人类专家深度协同(修复各种bug)
- 缓解幻觉,应该给LLM留退路(unknown)
- 按照任务维度打分,每个维度单独一个LLM-as-judge
- 具备防作弊,防绕过能力
- 谨慎使用人工评分
- 结果导向,防止扼杀创造性
- 评估长期维护和使用
- 检查完成交互记录
- anthropic定期仔细审阅,确定评分器的有效性
- 监控能力评估饱和现象(即100分不等于100分)
- anthropic原则,再深入评估细节、审阅记录前,不轻信任何分数
- 通过开放贡献和维护保持评估长期健康
- 评估套件必须是活的
- anthropic设立专职评估团队负责核心infra,由领域专家和产品团队贡献绝大多数任务
- 践行评估驱动开发
- 当前专注临时可用,押宝未来及基模型升级
- 最贴近产品的人才能定义成功。借助vibcoding,人人都能提pr
- 检查完成交互记录
除自动化评估外,还需要
Automated evalsRunning tests programmatically without real usersProduction monitoringTracking metrics and errors in live systemsA/B testingComparing variants with real user trafficUser feedbackExplicit signals like thumbs-down or bug reportsManual transcript reviewHumans reading through agent conversationsSystematic human studiesStructured grading of agent outputs by trained raters