数学基础
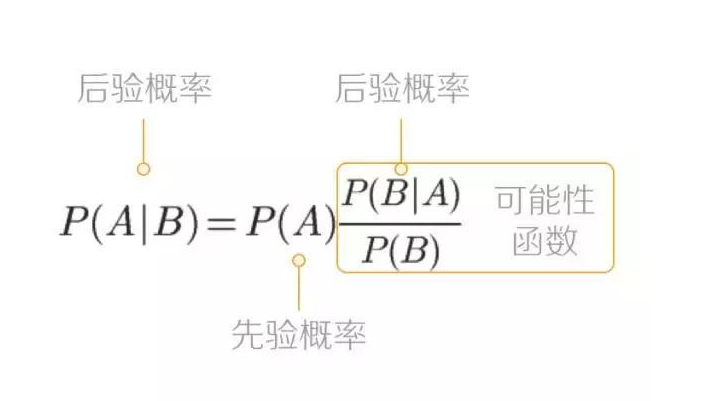
先验概率: 根据以往的经验分析得到的概率;
后验概率:根据结果推导原因;
贝叶斯公式:
核心原理
朴素贝叶斯法通过训练数据集学习联合概率分布P(X,Y),具体的学习先验概率分布
P(Y=ck),k=1,2,⋯,K
条件概率分布
P(X=x∣Y=ck)=P(X(1)=x(1),⋯,X(n)=x(n)∣Y=ck),k=1,2,⋯,K
于是学习到联合概率分布P(X,Y)
实际上,朴素贝叶斯对条件概率分布做了条件独立性的假设,这一假设使得朴素贝叶斯发相对简单;但也会牺牲一定的分类准确率;
朴素贝叶斯法分类时,对于给定的输入x,通过学习到的模型计算后验概率分布,将后验概率最大的类作为x的输出类。具体的朴素贝叶斯分类器可以表示为
y=f(x)=argckmax∑kP(Y=ck)j∏P(X(j)=x(j)∣Y=ck)P(Y=ck)j∏P(X(j)=x(j)∣Y=ck)
由于上式中所有分母都是相同的,因此上式等价于
y=argckmaxP(Y=ck)j∏P(X(j)=x(j)∣Y=ck)
后验概率最大化等价于经验风险最小化(后验概率最大化的含义)

朴素贝叶斯的参数估计
极大似然估计
-
计算先验概率及条件概率
P(Y=ck)=Ni=1∑NI(yi=ck),k=1,2,⋯,K
P(X(j)=ajl∣Y=ck)=i=1∑NI(yi=ck)i=1∑NI(xi(j)=ajl,yj=ck)j=1,2,⋯,n;l=1,2,⋯,Sj;k=1,2,⋯,K
-
对于给定的实例x=(x(1),x(2),⋯,x(n))T,计算
p(Y=ck)j=1∏nP(X(j)=x(j)∣Y=ck),k=1,2,⋯,K
-
确定实例x的类
y=argckmaxP(Y=ck)j=1∏nP(Xj=xj∣Y=ck)
贝叶斯估计
极大似然估计可能会出现要估计的概率值为0的情况,这会影响到后验概率的计算结果。使分类产生偏差。可以用贝叶斯估计来解决这一问题;具体的
先验概率的贝叶斯估计是
Pλ(Y=ck)=N+Kλi=1∑NI(yi=ck)+λ
条件概率的贝叶斯估计是
Pλ(X(j)=ajl∣Y=ck)=i=1∑SjI(yi=ck)+Sjλi=1∑NI(xi(j)=ajl,yi=ck)+λ
其中,λ≥0,相当于在随机变量各个取值上赋予一个整数λ>0.当λ=0时就是极大似然估计;常取λ=1,这时称为拉普拉斯平滑。显然
Pλ(X(j)=ajl∣Y=ck)>0j=1∑SjP(X(j)=ajl∣Y=ck)=1

